728x90
반응형
https://arxiv.org/pdf/2604.18584
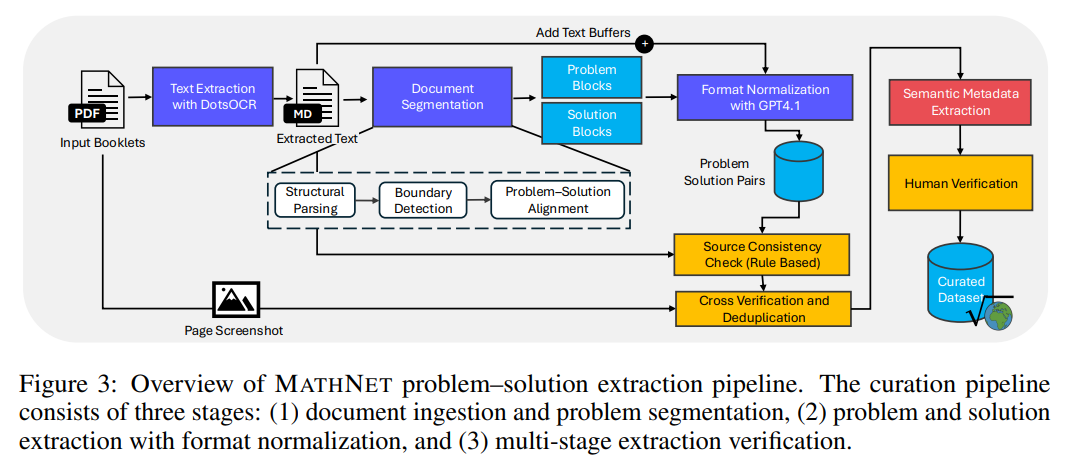
MATHNET은 전 세계 47개국에서 40년 동안 수집된 3만 개 이상의 고난도 올림피아드 수학 문제를 포함하는 대규모 다국어 멀티모달 데이터셋이자 벤치마크입니다. 이 프로젝트는 단순한 정답 도출을 넘어, 17개 언어로 구성된 방대한 자료를 바탕으로 인공지능의 수학적 추론 능력과 문제 검색 성능을 정밀하게 측정하는 것을 목적으로 합니다. 특히 텍스트의 표면적인 유사성에 속지 않고 문제의 심층적인 구조적 동등성을 식별하는 '수학 인지 검색' 작업을 도입하여 기존 모델들의 한계를 분석합니다. 인간 전문가가 작성한 고품질 해설과 세분화된 유형 분류를 제공함으로써, MATHNET은 향후 검색 증강 생성(RAG) 기술을 통한 복합적인 수학 문제 해결 능력 발전에 중요한 토대를 마련하고 있습니다.
https://huggingface.co/datasets/ShadenA/MathNet
https://github.com/ShadeAlsha/MathNet


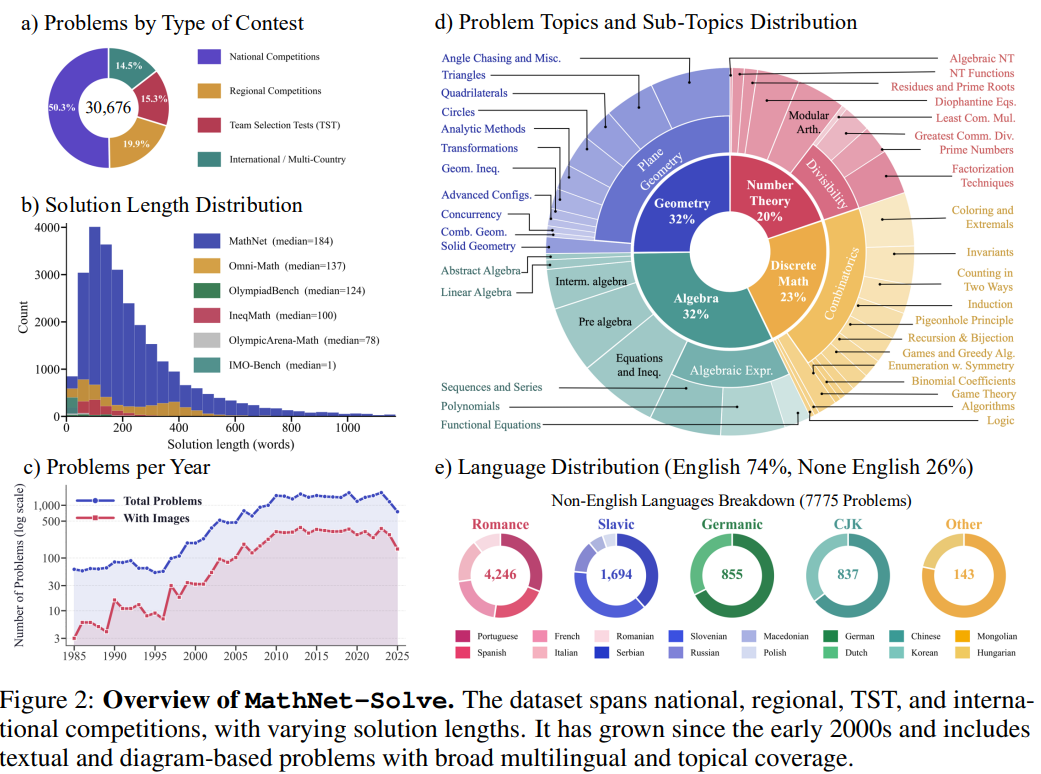
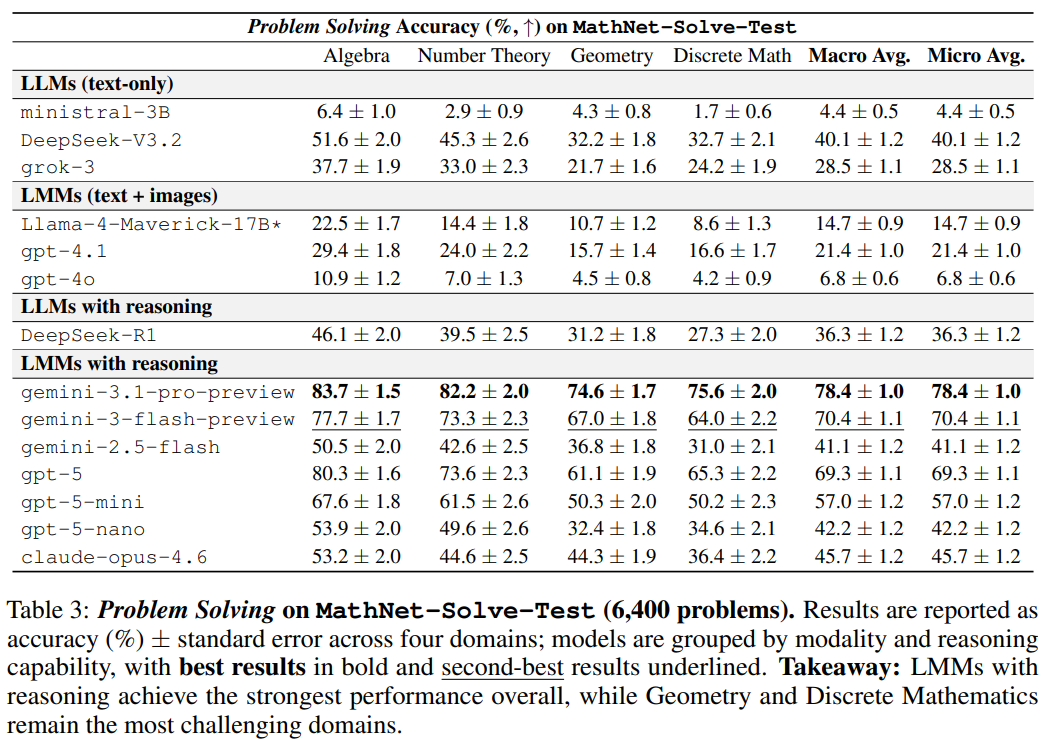


테스트 결과, 현존 최고 사양인 GPT-5조차 매스넷의 6,400개 핵심 문제에서 평균 69.3%의 정답률에 머물렀다. 올림피아드 수준의 문제 3개 중 1개는 여전히 풀지 못한다는 의미다. 특히 문제가 그림이나 도표를 포함하는 경우 모든 모델의 성능이 급격히 하락하여, AI의 ‘시각적 추론’ 능력이 여전히 해결해야 할 과제임을 드러냈다. 언어 장벽 문제도 지적되었다. 일부 오픈소스 모델들은 몽골어와 같은 비주류 언어로 된 문제에서 0%의 정답률을 기록했다. 이는 AI 학습 데이터가 특정 언어와 문화권에 편중되어 있음을 시사한다. 매스넷은 단순한 문제 풀이를 넘어, 두 문제가 동일한 수학적 구조를 공유하는지 식별하는 ‘검색(Retrieval)’ 벤치마크도 도입했다. 테스트 결과, 최첨단 임베딩 모델들도 구조적 동등성을 단번에 찾아낼 확률이 5%에 불과한 것으로 나타났다.
출처: 인공지능 신문















728x90
'07.AI > 7. AI 벤치마크' 카테고리의 다른 글
| LLM - 성능 - 벤치마크 - EPOCH AI, Domain-specific ECI (0) | 2026.05.13 |
|---|---|
| LLM - 성능 - 벤치마크 - Comet, Opik 멀티모달 대형 언어 모델(MLLM) 개발자 가이드 (0) | 2026.05.12 |
| LLM - 성능 - 벤치마크 - LongCoT, 장기적인 추론 능력? (1) | 2026.05.09 |
| LLM - 성능 - 벤치마크 - ARC-AGI-3 (0) | 2026.05.07 |
| LLM - 성능 - 벤치마크 - AI 벤치마크는 실패할 운명인가? (0) | 2026.05.02 |




