728x90
반응형
https://www.alphaxiv.org/abs/2604.14140
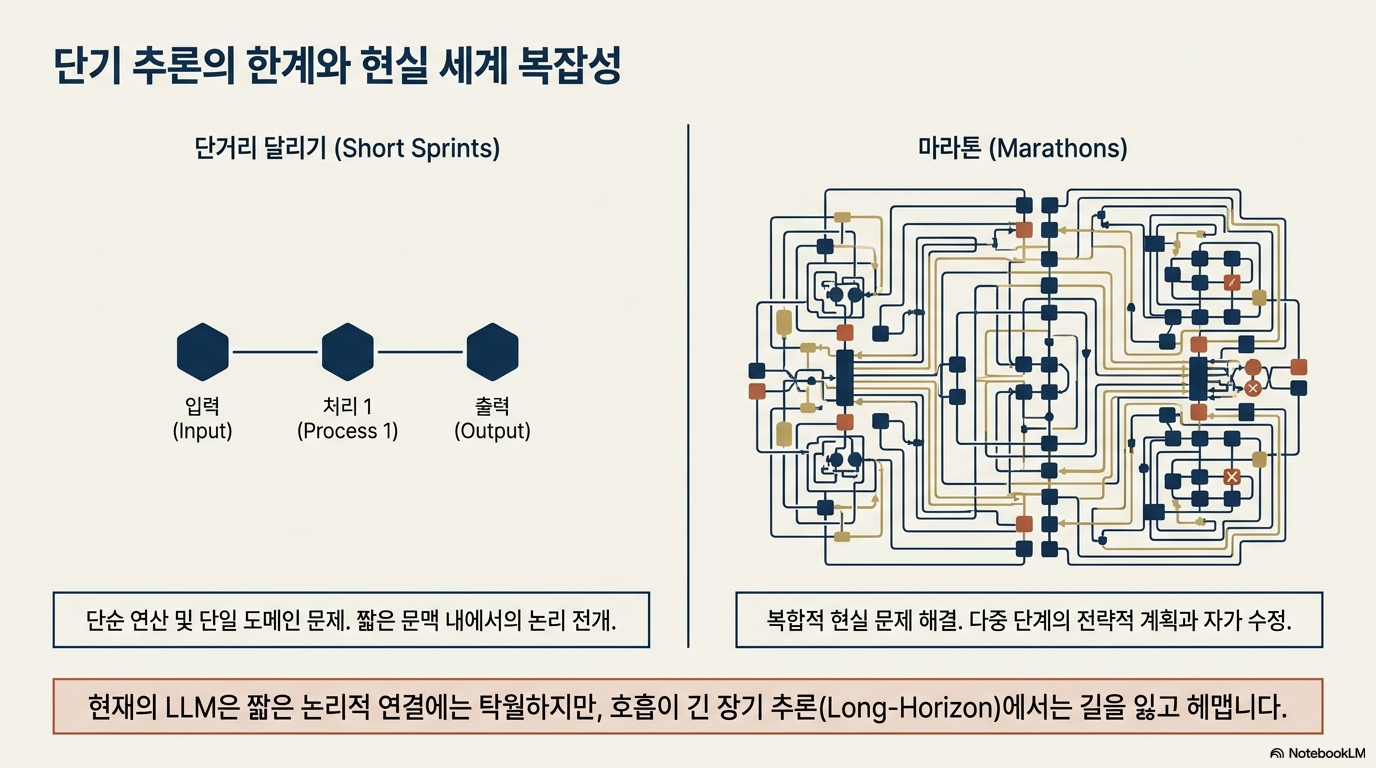
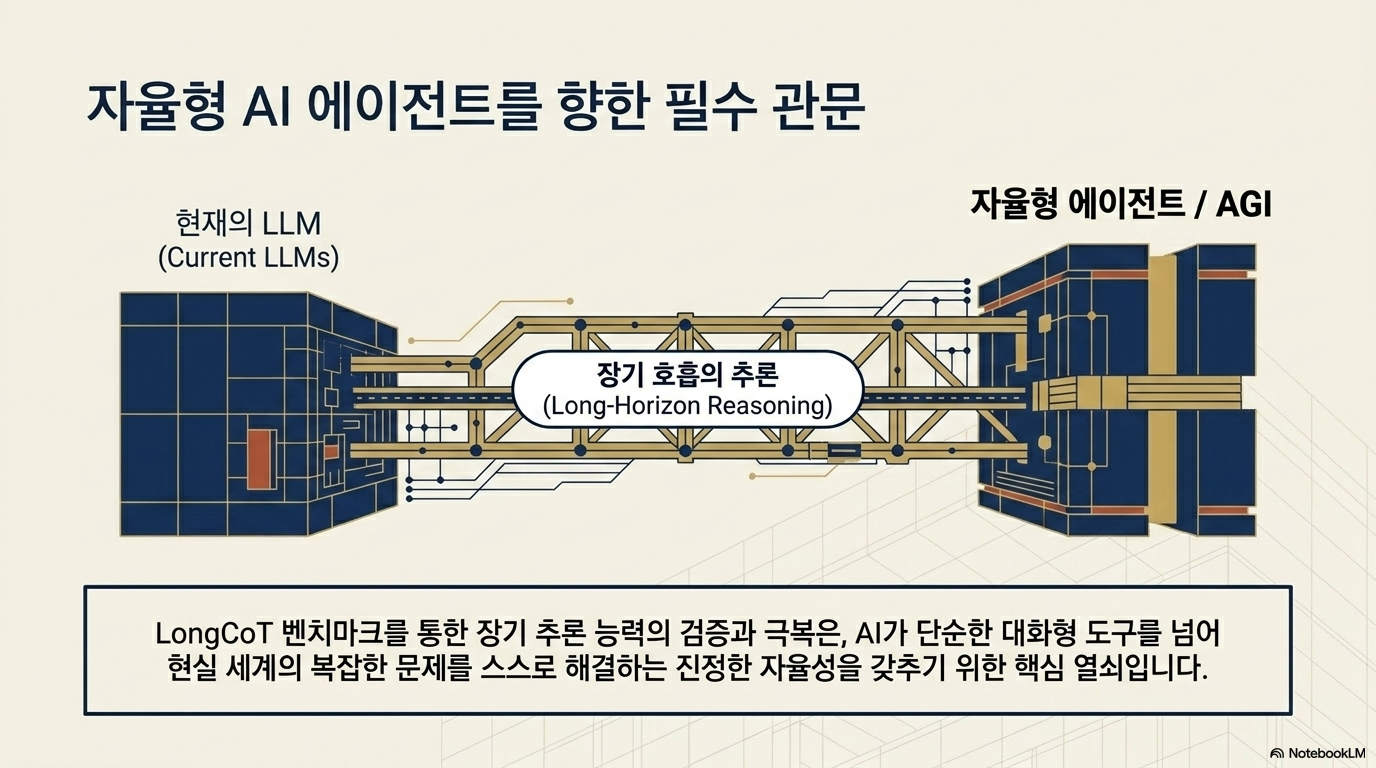
이 자료는 인공지능이 복잡한 문제를 해결할 때 거치는 단계별 사고 과정, 즉 '체인 오브 서트(Chain-of-Thought)' 능력을 정밀하게 측정하기 위한 새로운 평가 체계인 LongCoT를 소개합니다. 연구의 핵심은 단순히 정답을 맞히는 것을 넘어, 모델이 긴 호흡의 논리적 추론을 얼마나 일관성 있게 유지하며 결론에 도달하는지 분석하는 데 목적이 있습니다. 이를 통해 고도화된 지능형 모델들이 마주하는 장기적 문제 해결 능력의 한계를 진단하고, 더 깊이 있는 사고를 유도하는 벤치마크로서의 역할을 수행합니다. 따라서 이 텍스트는 현대 AI 기술의 추론 효율성과 논리적 깊이를 검증하기 위한 필수적인 기준점을 제시하고 있습니다.
Measuring and Improving Long-Horizon Reasoning Capabilities · Zoom · Luma
About Event 🔬 AI4Science on alphaXiv 🗓 Friday May 15th 2026 · 11 AM PT 🎙 Featuring Sumeet Motwani and Charles London 💬 Casual Talk + Open Discussion 🎥…
luma.com




728x90
'07.AI > 7. AI 벤치마크' 카테고리의 다른 글
| LLM - 성능 - 벤치마크 - Comet, Opik 멀티모달 대형 언어 모델(MLLM) 개발자 가이드 (0) | 2026.05.12 |
|---|---|
| LLM - 성능 - 벤치마크 - MATHNET, 수학적 추론 AI 벤치마크 (0) | 2026.05.09 |
| LLM - 성능 - 벤치마크 - ARC-AGI-3 (0) | 2026.05.07 |
| LLM - 성능 - 벤치마크 - AI 벤치마크는 실패할 운명인가? (0) | 2026.05.02 |
| LLM - 성능 - 벤치마크 - RLI, GDPval, APEX-Agents 경제가치 분석 (0) | 2026.05.02 |




