728x90
반응형
(개념) 인공지능이 인간의 가치, 의도, 윤리, 사회적 목표와 일치하도록 설계·운용하는 연구 분야
- AI alignment의 목적은 AI가 인간의 목표를 벗어나서 오작동하거나 예기치 않은 결과(예: 보상 해킹)를 일으키지 않도록 하는 것이다. 즉, AI가 인간의 의도를 왜곡 없이 따르도록 보장하는 기술적·윤리적 접근이다.

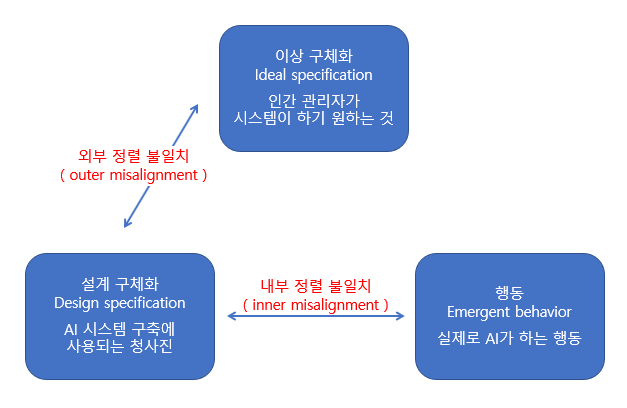
AI alignment는 보통 두 가지 범위로 나뉜다.
- 좁은 의미의 정렬(narrow alignment): 특정 작업에서 사용자의 선호나 지시를 정확히 따르도록 조정하는 것. 예컨대 챗봇이 사용자의 질문에 정직하고 정확하게 답변하도록 만드는 방식이다.
- 넓은 의미의 정렬(ambitious alignment): 초지능 수준의 AI가 스스로 의사결정을 내리는 상황에서도 인류 전체의 복지와 가치와 일치하게 작동하도록 하는 연구로, 윤리학과 철학 영역까지 확장된다. 스튜어트 러셀은 “AI 시스템은 인간 선호의 최대 실현을 목표로 설계되어야 한다”고 강조했다.
728x90
'12. 메일진 > 7. AI Safety' 카테고리의 다른 글
| AI 안전성 - ISO/IEC JTC 1/SC 42 (0) | 2025.12.22 |
|---|---|
| AI 안전성 - 위험 관리 - TTA, AssurAI 데이터셋 (멀티모달 생성형 AI 위험 평가용 데이터셋) (0) | 2025.11.25 |
| AI 안전성 - 위험 관리 - 가디언 모델(Guardian Model) (0) | 2025.09.29 |
| AI 안전성 - 위험 관리 - AI 안전 기술 동향과 향후 과제 (D) (0) | 2025.08.02 |
| AI 안전성 - 위험 관리 - 오픈AI, 세이프티 평가 허브(Safety Evaluations Hub) (0) | 2025.05.24 |




