CWM: An Open-Weights LLM for Research on Code Generation with World Models
| Date: September 29, 2025 Inference Code: github.com/facebookresearch/cwm Model Weights: http://ai.meta.com/resources/models-and-libraries/cwm-downloads, huggingface.co/facebook/cwm, ../cwm-sft, ../cwm-pretrain |
(개념) 코드 생성 연구를 발전시키기 위해 Meta FAIR CodeGen 팀이 공개한 320억 개의 파라미터를 가진 오픈 가중치 LLM
- 코드가 무엇을 하는지에 대한 세계 모델링을 통해 코드 생성 연구를 발전시키기 위해 출시된 320억 개의 파라미터를 가진 오픈 가중치 LLM
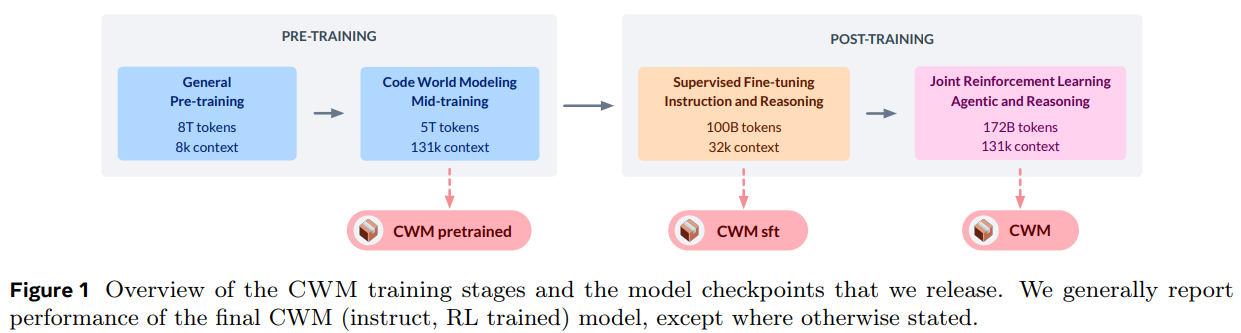
| 정적 코드만으로 학습된 코드 이해도를 넘어서기 위해 Python 인터프리터 및 에이전트 Docker 환경에서 대량의 관찰-행동(observation-action) 궤적을 mid-training하고, 검증 가능한 코딩, 수학, 다중 턴 소프트웨어 엔지니어링 환경에서 광범위한 다중 작업 추론 RL(Reinforcement Learning)을 수행했다. 이는 계산 환경에서 추론 및 계획을 통해 코드 생성을 개선하는 데 월드 모델링이 제공하는 기회를 탐색하기 위한 강력한 테스트베드를 제공한다. |
- Python 인터프리터 및 에이전트 Docker 환경에서 대량의 관찰-액션 궤적 데이터를 활용하는 독자적인 '미드 트레이닝' 과정을 거쳐 코드 실행의 의미론적 이해를 향상하며, 광범위한 다중 작업 추론 RL을 수행
- SWE-bench Verified, LiveCodeBench 등 일반 코딩 및 수학 과제에서 동급 오픈 모델을 능가하고 대규모 모델과도 경쟁하는 강력한 성능을 보이며, 코드 세계 모델링 연구를 위한 테스트베드를 제공



이 부분은 CWM의 핵심 블록 구조를 설명합니다: Grouped‑Query‑Attention(GQA)를 쓰고, "지역(local)" 8k 토큰 어텐션과 "전역(global)" 131k 토큰 슬라이딩 어텐션을 교대로 배치한 구조입니다.
- 블록 구성 (문장 분석)
"Global SWA (131k tokens) + FFN" → "Local SWA (8k) + FFN" ×3 → (임베딩/출력) 형태로 블록이 쌓이며, 이 패턴을 여러 번(문맥에서 반복 15회 등) 반복합니다.
여기서 SWA는 문맥상 "sliding window attention"을 의미합니다(=슬라이딩 윈도우 어텐션). 각 어텐션 블록 뒤에 FFN(feed‑forward) 층이 붙습니다.
- 지역 vs 전역 어텐션의 역할
Local (8k): 근접 토큰 간의 세밀한 상호작용을 효율적으로 처리. 연산량·메모리 비용이 상대적으로 작음.
Global (131k): 장거리 의존성(문서 전체, 긴 코드/테스트 로그 등)을 포착. 동적 슬라이딩 윈도우로 아주 긴 컨텍스트를 지원함.
교대로 배치함으로써 장문맥을 처리하는 비용을 줄이면서도 전역 정보를 전달할 수 있도록 설계됨.
- Grouped‑Query‑Attention(GQA)와 하이퍼 파라미터
GQA: 쿼리 헤드를 여러 그룹으로 묶어 키/값와 분리된 헤드 수를 둬 연산/메모리 효율을 높이는 기법.
본문 표기에 따른 설정: query heads = 48, key‑value heads = 8 (즉, 쿼리 헤드는 많고 KV는 축약).
기타: SwiGLU 활성화, RMSNorm, RoPE(Scaled RoPE) 등 장문맥·학습 안정성 관련 구성 사용.
- 컨텍스트 길이·토크나이저·임베딩
로컬 윈도우: 8,192 토큰, 글로벌 윈도우(최대): 131,072 토큰.
토크나이저/어휘: 128k vocab(embedding 및 output proj 포함).
mid‑training 때부터 Scaled RoPE 적용(θ = 1e6, scale factor 16)으로 긴 컨텍스트 학습 안정화.
- 왜 이렇게 설계했나 (동기)
코드/실행 추적, 에이전트-환경 상호작용 같은 장문맥·상태-행동(Observation‑Action) 데이터가 많기 때문에, 전체 문서를 한 번에 커버하면서도 계산을 통제 가능한 구조가 필요했음.
지역 블록은 국소적 프로그램 상태·문법을, 전역 블록은 장기 플로우(예: 여러 파일·커밋·테스트 로그)를 포착하도록 의도됨.
- 그림 6(b)에 나타난 입력/출력 타입(간단 해석)
기호 P/T/O는 훈련/추론에서 다루는 데이터 타입을 나타냄:
P = Prompt(프롬프트), T = Text / Code(문서·코드·설명), O = Observations(실행 관찰 상태: 변수, 테스트 출력 등).
- 전(Pre)‑학습: 주로 일반 텍스트·코드(T).
- 중간(Mid)‑학습: 코드 실행 트레이스와 ForagerAgent의 관찰‑행동(O) 데이터를 대거 투입하여 world‑model 능력 강화(동시에 더 긴 컨텍스트 사용).
- 후(Post)‑학습(RL/SFT): 에이전트식 상호작용(혼합된 T/O)으로 실제 도구 사용·추론 능력 향상.
결과적으로 모델은 텍스트/코드/관찰을 섞은 입력을 처리하고, 실행 추적을 예측하거나 에이전트 행동을 생성하는 등 다양한 입출력 패턴을 다룰 수 있음.
실무적 함의(요약)
이 교차(local/global) 설계로 CWM은 긴 로그·테스트·커밋 이력 같은 장문맥을 보면서도 계산 효율을 유지할 수 있고, 그 덕에 코드 실행 시뮬레이션(trace prediction)이나 장기 에이전트 RL에 적합한 내부 표현을 학습할 수 있습니다.
- 참고 수치(핵심)
파라미터 수: 32B, 레이어 수 표기(문맥상 64), 로컬 윈도우 8k, 글로벌 윈도우 131k, vocab=128k, GQA heads (48/8).

'07.AI' 카테고리의 다른 글
| 생성형 AI - 월드 모델 (World Model) - 공동 임베딩 예측 아키텍처(JEPA) (0) | 2025.10.28 |
|---|---|
| LLM - Open AI, GPT-OSS (5) | 2025.10.08 |
| 머신러닝 - 파인튜닝 - ORPO(Odds Ratio Preference Optimization) 방식 (0) | 2025.09.25 |
| LLM - 시각-언어 모델(Vision Language Model: VLM) - Paper (0) | 2025.09.24 |
| LLM - Open AI, GPT-5 (1) | 2025.09.08 |




