http://www.aitimes.kr/news/articleView.html?idxno=17276
페이스북 AI, 딥러닝으로 하나의 컴퓨터 언어를 다른 언어로 번역하는 '트랜스코더' 오픈 소스로
페이스북이 구식 코드베이스를 현대 언어로 번역하기 위한 '트랜스코더(TransCoder)'라고 하는 오픈 소스 도구를 개발하고 최근 공개했다. 이 플랫폼은 코드 마이그레이션을 보다 쉽고 효율적으...
www.aitimes.kr
facebookresearch/TransCoder
Public release of the TransCoder research project https://arxiv.org/pdf/2006.03511.pdf - facebookresearch/TransCoder
github.com
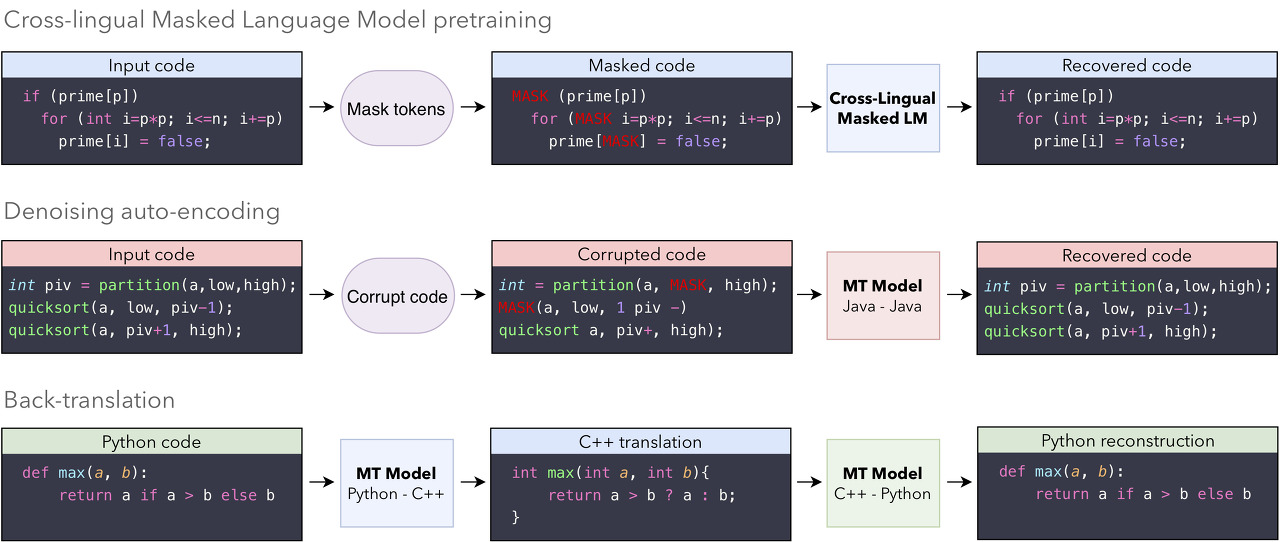
Run an evaluation
- Download the test and validation data and unzip it. In that folder, the test and validation data are preprocessed (tokenized , BPE applied) and binarized to be used directly in XLM and to test the released model. We also release the raw data here.
- put all the binarized data into data/XLM-cpp-java-python-with-comments
- run XLM/train.py in eval_only mode. For instance:
python XLM/train.py --n_heads 8 --bt_steps 'python_sa-cpp_sa-python_sa,cpp_sa-python_sa-cpp_sa,java_sa-cpp_sa-java_sa,cpp_sa-java_sa-cpp_sa,python_sa-java_sa-python_sa,java_sa-python_sa-java_sa' # The evaluator will use this parameter to infer the languages to test on --max_vocab '-1' --word_blank '0.1' --n_layers 6 --generate_hypothesis true --max_len 512 --bptt 256 --fp16 true --share_inout_emb true --tokens_per_batch 6000 --has_sentences_ids true --eval_bleu true --split_data false --data_path 'path_to_TransCoder_folder/data/XLM-cpp-java-python-with-comments' --eval_computation true --batch_size 32 --reload_model 'model_1.pth,model_1.pth' --amp 2 --max_batch_size 128 --ae_steps 'cpp_sa,python_sa,java_sa' --emb_dim 1024 --eval_only True --beam_size 10 --retry_mistmatching_types 1 --dump_path '/tmp/' --exp_name='eval_final_model_wc_30' --lgs 'cpp_sa-java_sa-python_sa' --encoder_only=False
Download/preprocess data
To get the monolingual data, first download cpp / java / python source code from Google BigQuery (https://cloud.google.com/blog/products/gcp/github-on-bigquery-analyze-all-the-open-source-code). To run our preprocessing pipeline, you need to donwlaod the raw source code on your machine in json format, and put each programming language in a dedicated folder. A sample of it is given in data/test_dataset. The pipeline extracts source code from json, tokenizes it, extracts functions, applies bpe, binarizes the data and creates symlink with appropriate name to be used directly in XLM. The folder that ends with .XLM-syml is the data path you give for XLM traning. You will have to add the test and valid parallel we provide in "Run an evaluation" data to that folder.
To test the pipeline run pytest preprocessing/test_dataset.py, you will see the pipeline output in data/test_dataset folder.
License
TransCoder is under the license detailed in the Creative Commons Attribution-NonCommercial 4.0 International license. See LICENSE for more details.
'07.AI' 카테고리의 다른 글
| 딥러닝과 자연어 처리 학습을 위한 자료 저장소 (1) | 2020.08.19 |
|---|---|
| 딥 러닝을 이용한 자연어 처리 입문 (0) | 2020.08.18 |
| 자연어처리 (NLP) - BERT (0) | 2020.08.04 |
| 유사도(Similarity) 계산 방식 (0) | 2020.07.27 |
| 딥러닝 - RNN (순환신경망, Recurrent Neural Network) (0) | 2020.07.16 |




