728x90
반응형
https://arxiv.org/abs/2603.09906
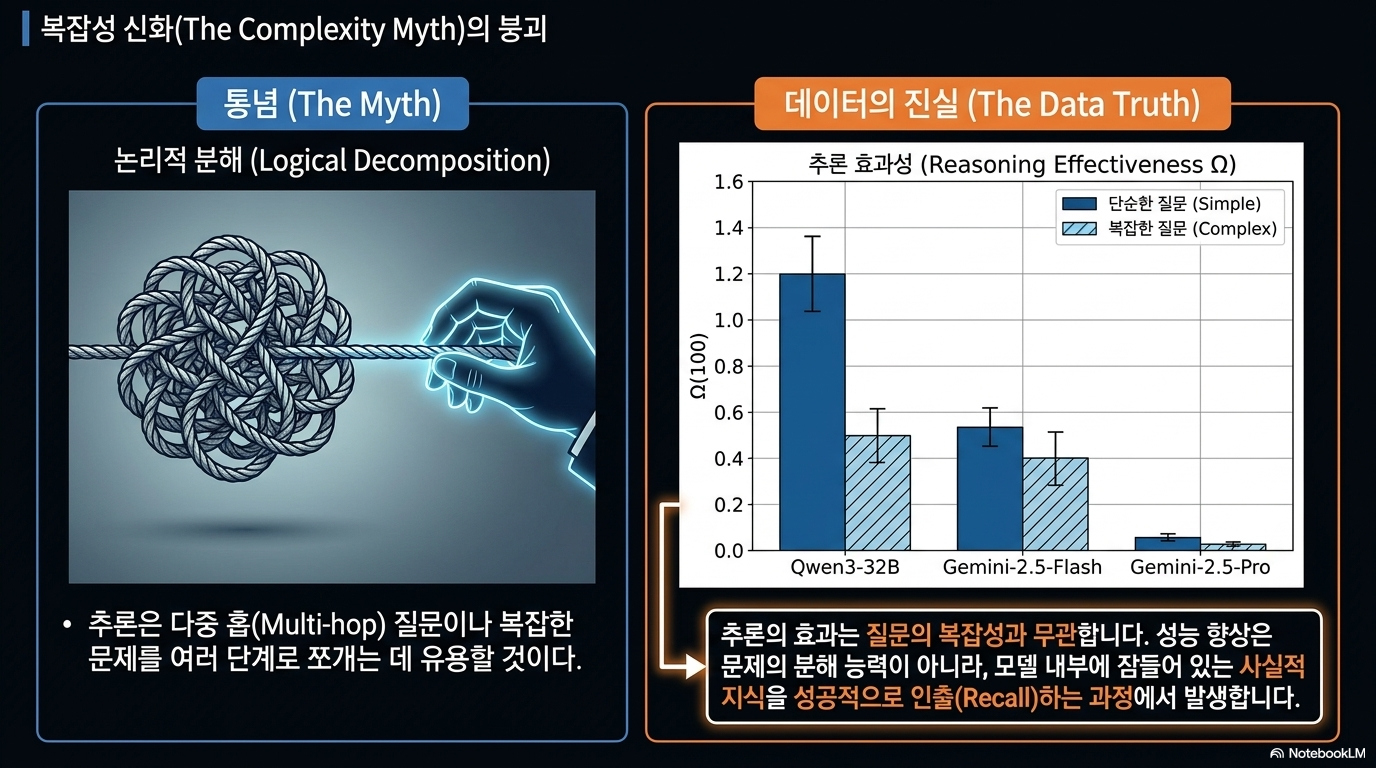
2026.3.10 [Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs] 이 논문은 거대언어모델(LLM)이 단계별 논리 분해가 필요 없는 단순한 사실 관계 질문에 답할 때에도 추론(Reasoning) 과정을 거치면 정답률이 비약적으로 상승하는 현상을 분석합니다. 연구진은 추론이 단순한 논리적 도구가 아니라 모델 내부의 잠재된 지식을 인출하는 핵심 열쇠임을 밝혀내며, 그 주요 기저 원리로 두 가지 메커니즘을 제시합니다. 첫째는 내용과 무관하게 추가 토큰을 생성하며 사고의 시간을 확보하는 계산 버퍼(Computational Buffer) 효과이며, 둘째는 관련 사실들을 떠올리며 정답에 접근하는 사실적 프라이밍(Factual Priming) 효과입니다. 하지만 추론 과정에서 허위 정보(Hallucination)가 섞일 경우 최종 답변의 신뢰도가 하락한다는 위험성도 함께 경고하며, 이를 바탕으로 더 정확한 지식 회복을 위한 실무적 개선 방향을 제안하고 있습니다.














728x90
'07.AI > 5. AI 자율성' 카테고리의 다른 글
| 프롬프트 엔지니어링 - LangChain, 루프 엔지니어링 (Loop Engineering) 의 미학 (0) | 2026.07.01 |
|---|---|
| 에이전트 AI - Z.ai, GLM-5.2 오픈 에이전트 (0) | 2026.07.01 |
| 에이전트 AI - 에이전트 기반 메모리 시스템 (0) | 2026.06.29 |
| 피지컬 AI (Physical AI) - ANSI, 자율주행과 첨단제조 분야 (0) | 2026.06.29 |
| 피지컬 AI (Physical AI) - 자율주행 웨이모(Waymo) (0) | 2026.06.29 |




