728x90
반응형
https://www.viksnewsletter.com/p/context-memory-storage-tokenomics
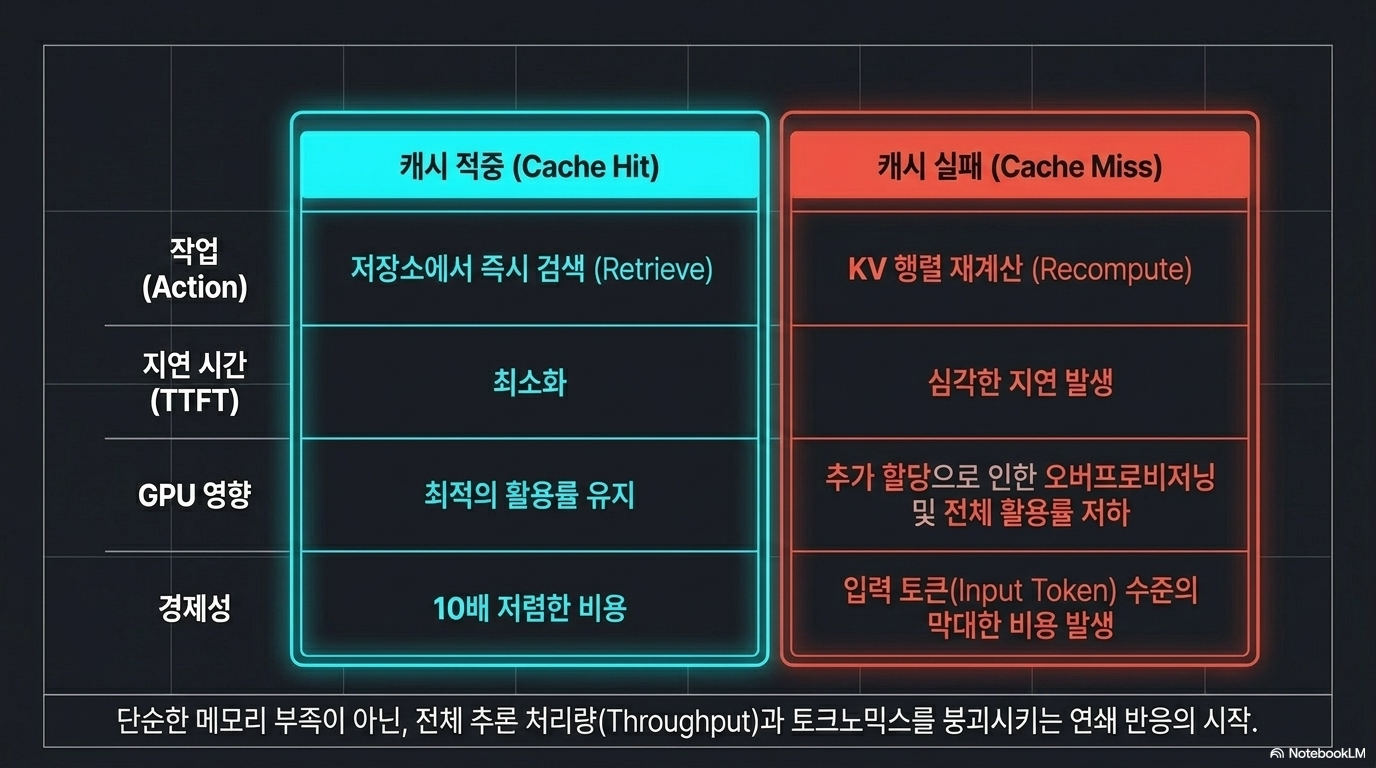
이 보고서는 에이전트 중심 AI(Agentic AI) 시대에 급증하는 데이터 처리 비용을 절감하기 위한 핵심 요소로 컨텍스트 메모리 저장 시스템의 혁신을 조명합니다. 텍스트는 엔비디아의 ICMS와 같은 신기술이 기존의 값비싼 DRAM 대신 저렴한 NAND SSD를 활용하여 KV 캐시(KV$)를 확장함으로써 대규모 언어 모델의 추론 경제성을 어떻게 변화시키는지 상세히 설명합니다. 특히 캐시 적중 실패 시 발생하는 10배의 비용 차이를 방지하는 것이 수익성의 관건이며, 이를 위해 효율적인 캐시 토큰 경제학(Cache Tokenomics)과 하드웨어 계층 구조의 최적화가 필수적임을 강조합니다. 결과적으로 이 자료는 하드웨어 인프라의 발전이 어떻게 긴 문맥 추론 서비스를 더 저렴하고 효율적으로 구현 가능하게 만드는지에 대한 기술적 및 경제적 통찰을 제공합니다.











728x90
'12. 메일진 > 3.AI 비용' 카테고리의 다른 글
| 비즈니스 - 토큰 경제 - 특이점의 경제학 (0) | 2026.05.26 |
|---|---|
| 2026 - 모델 랩(Model Lab) - AI 가치 (0) | 2026.05.26 |
| 생성형 AI - 추론 ‘inference’ 비용 - AI 가격 급락과 소프트웨어 혁신 (0) | 2026.05.23 |
| 2026 - 모델 랩(Model Lab) - 앤트로픽(Anthropic)의 비공개 벨류에이션 및 구조적 패러다임 변화 (0) | 2026.05.23 |
| 인공지능 - AI 반도체 - 글로벌 AI 칩 소유 현황 [프론티어 랩] (0) | 2026.05.23 |




