728x90
반응형
https://openai.com/index/introducing-swe-bench-verified/
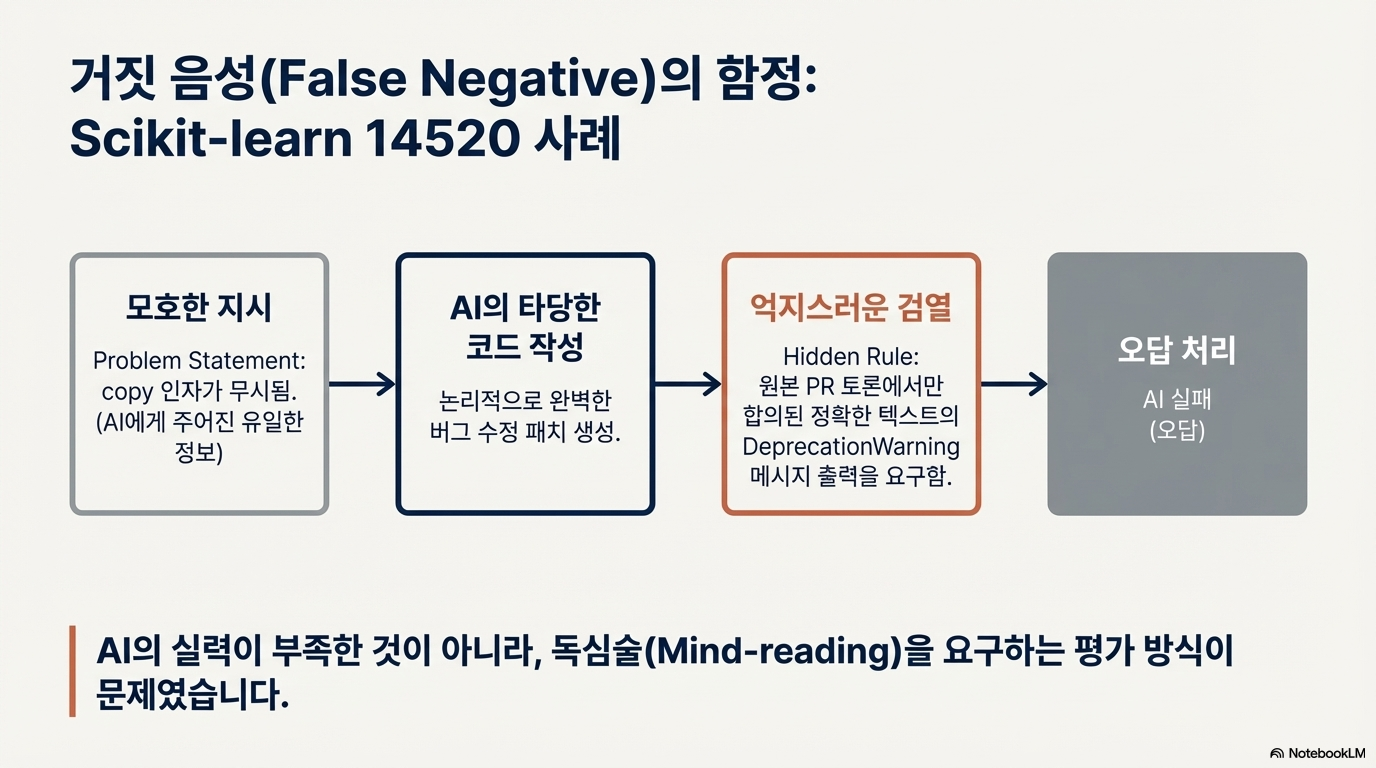
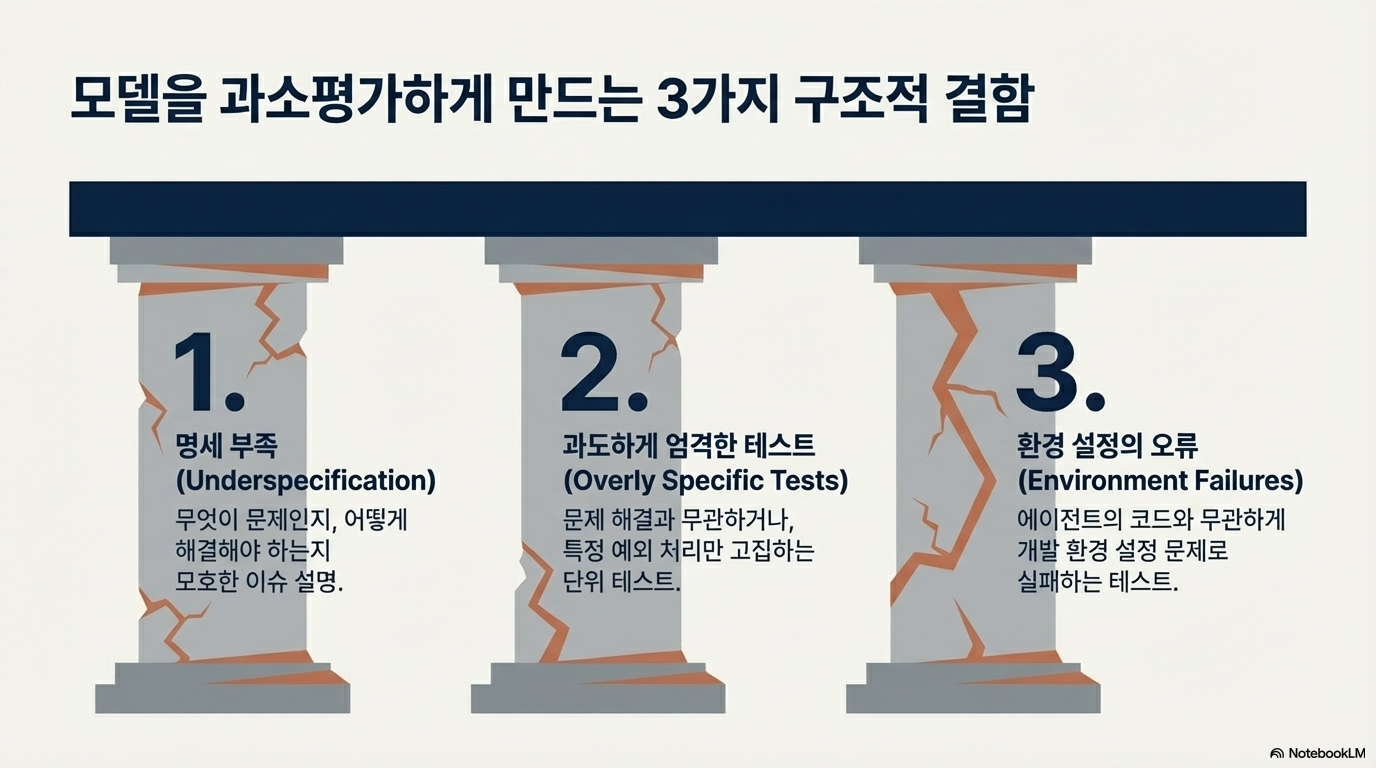
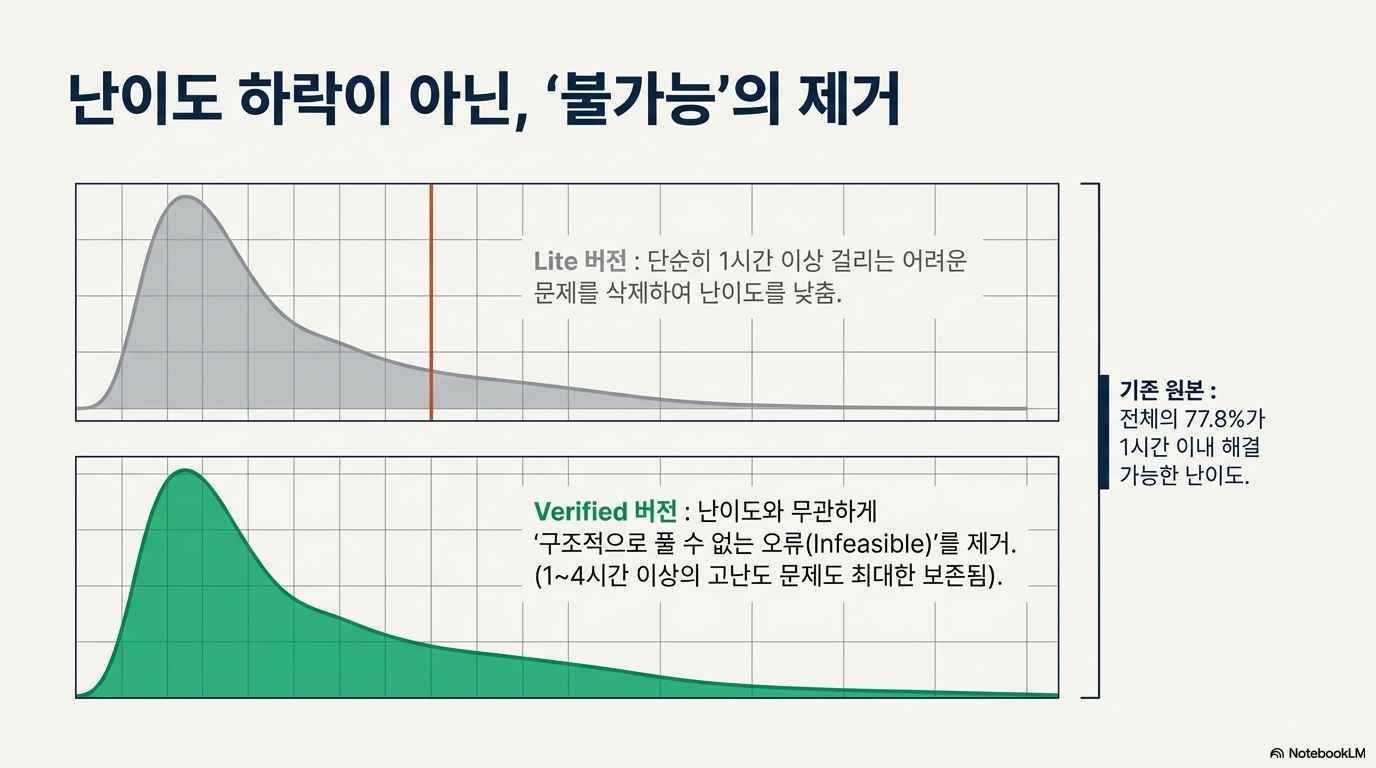
기존의 AI 소프트웨어 공학 능력 평가 도구인 SWE-bench의 한계를 보완하기 위해 OpenAI가 개발한 SWE-bench Verified를 소개합니다. 연구진은 인간 전문가의 검수를 통해 모호한 문제 설명이나 불합리한 테스트 기준을 가진 샘플들을 제거함으로써, 모델의 자율적인 문제 해결 능력을 더욱 정확하고 신뢰성 있게 측정할 수 있는 데이터셋을 구축했습니다. 이를 통해 GPT-4o와 같은 모델들의 성능이 기존 수치보다 높게 나타남을 증명하였으며, 이는 모델 자율성 위험 평가를 위한 객관적인 지표로 활용됩니다. 결과적으로 이 텍스트는 인공지능의 발전에 발맞추어 평가 체계의 정교화와 외부 시스템과의 결합을 통한 지속적인 성능 모니터링이 필수적임을 강조하고 있습니다.











728x90
'07.AI > 7. AI 벤치마크' 카테고리의 다른 글
| 성과측정 - AI 검증 및 평가 - OpenAI, SWE-bench Verified 오염 (0) | 2026.05.01 |
|---|---|
| LLM - 검색 증강 생성 (RAG) - 평가 - RAGEval (0) | 2026.04.05 |
| 성과측정 - AI 검증 및 평가 - AI 에이전트 SWE-rebench2 (0) | 2026.03.28 |
| 성과측정 - AI 검증 및 평가 - AI 에이전트 SWE-CI, EvoScore (0) | 2026.03.28 |
| 성과측정 - AI 검증 및 평가 - AI 에이전트 스킬 평가 및 테스트 실무 가이드 (0) | 2026.03.28 |




