728x90
반응형
https://arxiv.org/abs/2505.20411
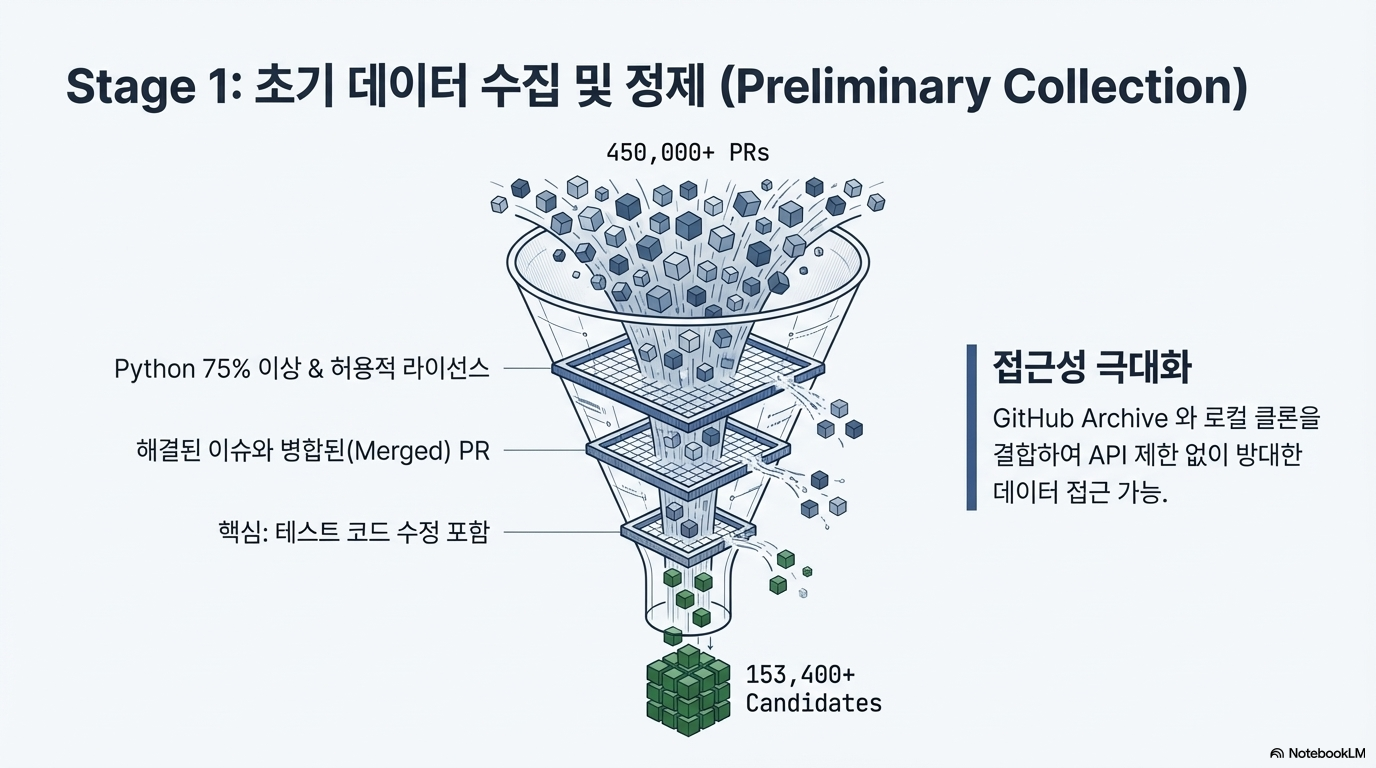
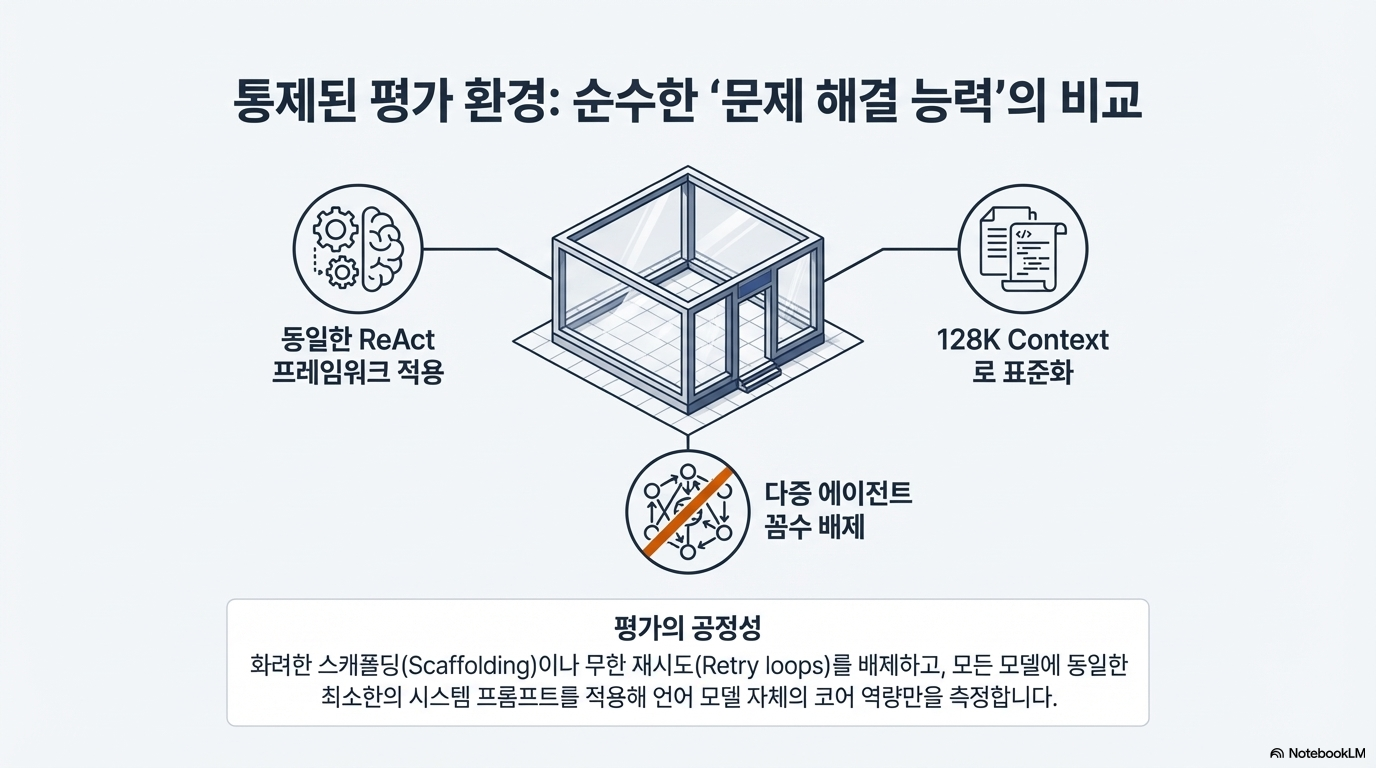
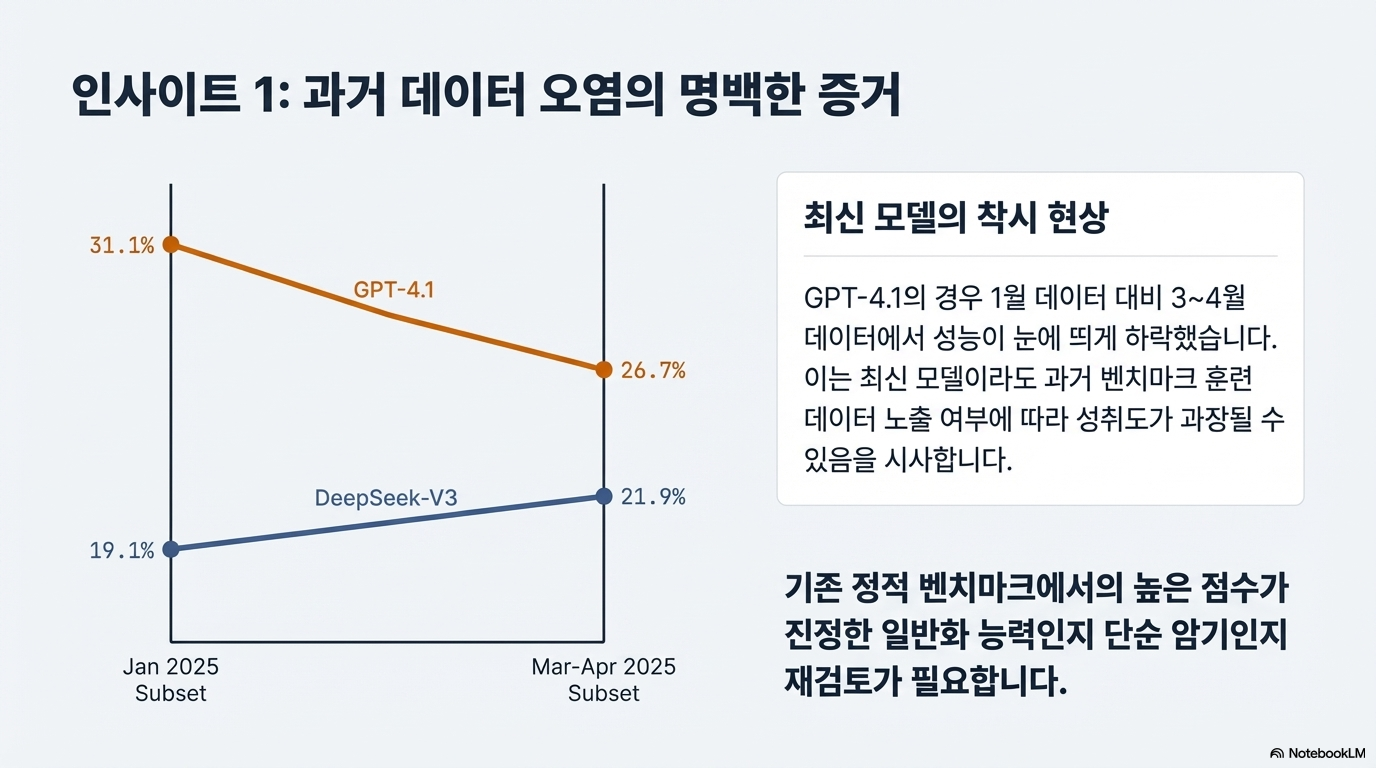
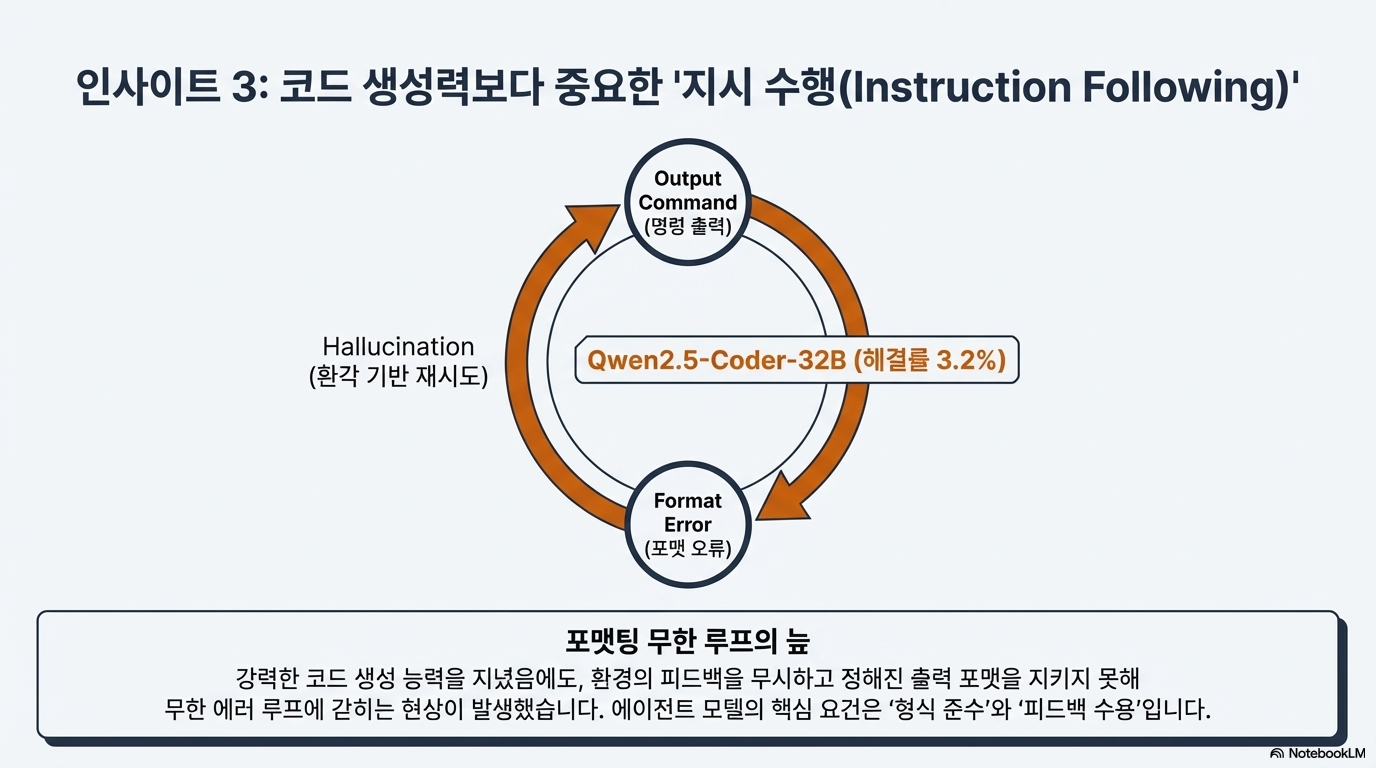
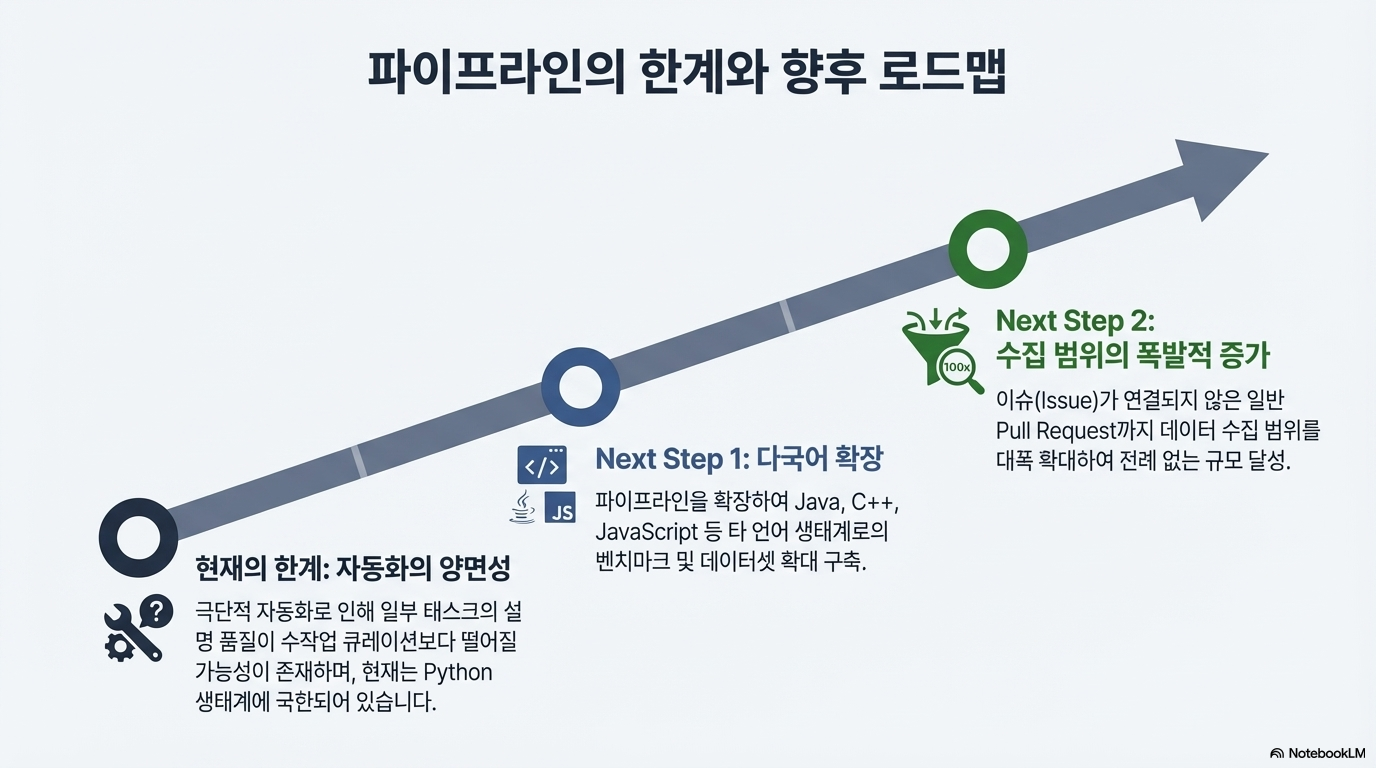
이 자료는 대규모 언어 모델(LLM) 기반 소프트웨어 공학 에이전트의 성능을 개선하고 평가하기 위한 SWE-rebench 파이프라인과 데이터셋을 소개합니다. 연구진은 기존 벤치마크의 데이터 오염 문제와 수동 구축의 한계를 해결하기 위해, GitHub에서 실제 과업을 지속적으로 추출하고 검증하는 완전 자동화된 시스템을 개발했습니다. 이를 통해 구축된 21,000개 이상의 파이썬 기반 과업은 에이전트의 강화 학습 및 정밀한 성능 측정에 활용됩니다. 또한, 최신 모델들을 대상으로 한 실험 결과, 일부 모델의 높은 성적이 과거 데이터에 대한 암기 효과일 수 있음을 시사하며 표준화된 평가 환경의 중요성을 강조합니다. 결론적으로 이 논문은 에이전트의 실질적인 문제 해결 능력을 투명하고 공정하게 비교할 수 있는 동적 벤치마크 시스템을 제안합니다.
















728x90
'07.AI > 7. AI 벤치마크' 카테고리의 다른 글
| 성과측정 - AI 검증 및 평가 - AI 에이전트 스킬 평가 및 테스트 실무 가이드 (0) | 2026.03.28 |
|---|---|
| 성과측정 - AI 검증 및 평가 - AI 에이전트의 실제 활용 : 평가 및 거버넌스 (0) | 2026.03.28 |
| LLM - 성능 - 벤치마크 - 데이터셋 가이드 (0) | 2026.02.20 |
| LLM - 성능 - 벤치마크 - 데이터 누수(Data Leakage) (0) | 2026.02.18 |
| LLM - 성능 - 벤치마크 - 벤치마크 데이터셋 현황 분석 및 정부 주도의 벤치마크 마련 필요성 (0) | 2026.02.14 |




