728x90
반응형
출처: 주간기술동향 2183호
발행: 2025.07.16
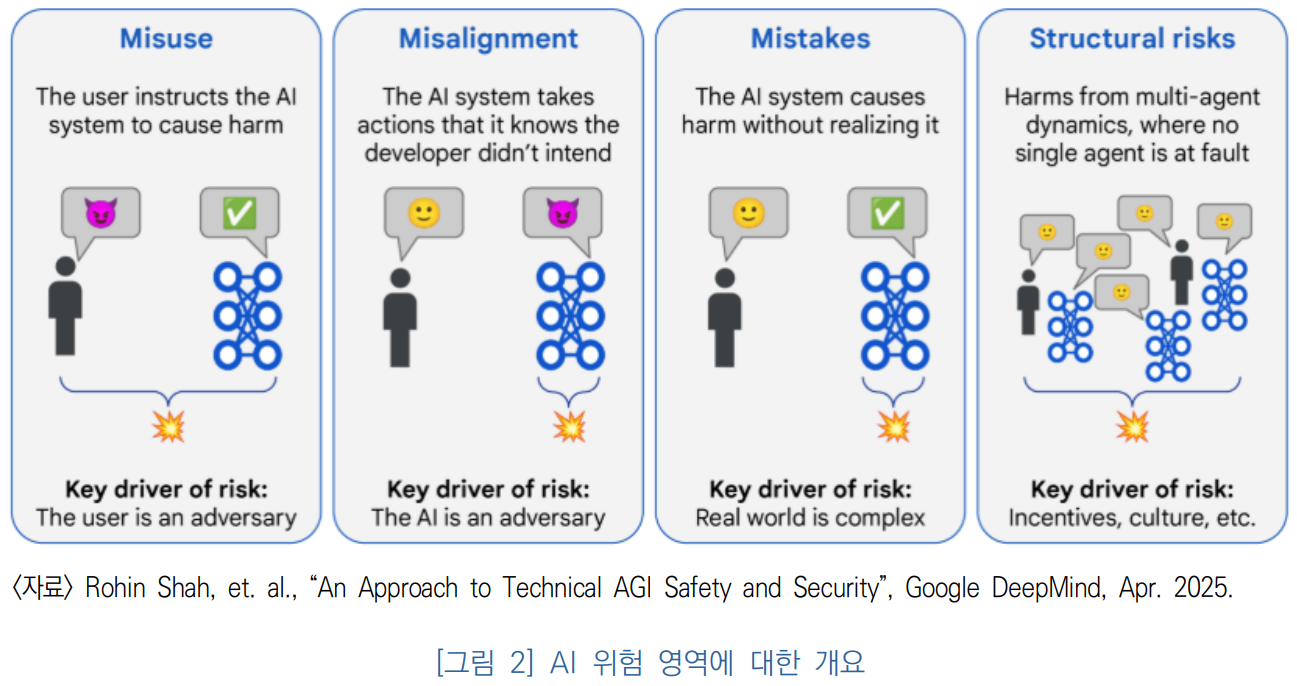

1. AI 안전 개념의 변화
- 초기 AI 안전 연구는 신뢰성(Reliability), 정확성(Accuracy), 오류 발생 최소화 등 기술적 오류 방지에 초점이 맞춰져 있었음.
- 그러나 최근 거대 언어 모델(LLM), 멀티모달 모델, AI 에이전트형 시스템의 등장으로 인해 기존 예측 범위를 초과하거나, 사회적·실존적 위협이 될 수 있는 새로운 위험 요소가 등장함.
- 이에 따라 안전 개념은 단순한 시스템 오류를 넘어서, 사회적 영향력, 자율적 행동 가능성, 통제 불가능성, 정보 유출 및 허위정보 생성 가능성까지 포함하는 확장된 개념으로 진화함.
| 구분 | 초기 AI 안전 연구 | 최근 AI 안전 연구 |
| 주요 초점 | 신뢰성, 정확성, 오류 발생 최소화 | 통제 불가능성, 정보 유출, 사회적 영향 등 |
| 주요 대상 | 협소한 시스템 단위 | LLM, 멀티모달 모델, AI 에이전트 |
| 문제 성격 | 예측 가능한 기술적 결함 | 예측 불가능한 실존 위험 (existential risk) 포함 |
2. 보고서의 목적
- 본 문서는 국제 협력 보고서(예: International AI Safety Report 2025, https://arxiv.org/abs/2501.17805) 및 주요 AI 기업의 연구 결과를 바탕으로,
- 현재 AI 안전 연구의 수준을 진단하고,
- AGI(Artificial General Intelligence) 도래를 대비한 핵심 안전 이슈 및 해결 과제를 정리함.
- 기술적 접근과 정책적 접근의 교차 분석을 통해 향후 글로벌 협력 및 기술 개발 방향성을 제시함.
3. AI 거버넌스 및 안전성 제도화
- 2019년 EU 집행위의 Trustworthy AI 가이드라인을 기점으로, 윤리·거버넌스 중심의 규범체계가 형성되기 시작함.
- 2023년 11월 영국 AI Safety Summit에서 AI 안전성은 국제 의제의 핵심으로 부상함.
- 특히 프론티어 AI 모델의 급속 성능 향상은 AI 안전성을 **초국가적 실존 리스크(existential risk)**로 인식하게 만듦.
- 이에 따라 영국이 선제적으로 AI Safety Institute를 설립했고,
- 미국, 캐나다, 싱가포르, 일본, **대한민국(2024.11)**도 AI 안전연구소 설립을 통해 글로벌 거버넌스에 참여함.
| 연도 | 사건 | 주요 내용 |
| 2019 | EU 「Trustworthy AI 지침」 발표 | AI 윤리 및 거버넌스 논의 본격화 |
| 2023.11 | 영국 AI Safety Summit | 프론티어 AI의 위험성을 실존 리스크로 인식 |
| 2024.11 | 한국 AI 안전연구소 출범 | 세계 6번째, 글로벌 협력 동참 |
4. 국제 협력의 흐름과 변화
- 2024년 11월 미국 샌프란시스코에서 AI 안전연구소 간 네트워크 구성
- 2024년 5월 **AI 안전 정상회의(서울)**에서는 AI 안전 논의가 혁신, 포용성 등 broader AI governance agenda로 확장됨.
- 그러나 2025년 2월 파리 AI 액션 정상회의 이후, 미국 주도의 "개발 우선" 기조로 인해 AI 안전이 후순위로 밀리는 경향이 나타남.
- 이에 따라 각국의 대규모 AI 투자 발표와 함께 글로벌 협력 체계에 균열이 생기고 있으며,
- 다수 전문가들은 이에 실망감을 표하며 안전 경시 경향에 우려를 표명함.
- 영국은 이에 대응하여 AI 안전연구소를 'AI 보안연구소'로 명칭 변경, AI 안전을 국가 안보 차원의 과제로 천명함.
| 시점 | 주요 동향 |
| 2024.11 | 美 샌프란시스코, AI 안전연구소 네트워크 구성 |
| 2024.5 | 서울 AI 안전 정상회의: 혁신·포용 논의 확대 |
| 2025.2 | 파리 AI 액션 정상회의 이후: "개발 우선" 기조 확산, 안전 후순위화 우려 |
| 이후 | 英 AI 안전연구소 → "AI 보안연구소"로 명칭 변경, 국가 안보 차원 강조 |
5. 주요 보고서 및 기업 연구 동향
- 국제 AI 안전 보고서 2025 (International AI Safety Report 2025)
- 요수아 벤지오 교수 주도로 약 100명의 연구자가 참여
- 핵심 내용:
- AI 안전 연구의 필요성 및 리스크 유형 분류
- 기술적 접근법(모델 안전성, 학습 통제, alignment 등)
- 정책 수립의 어려움(예: 책임 주체 불분명성, 상호운용성 문제 등)
- AI 기업의 연구
- OpenAI, Google DeepMind, Anthropic 등은
- 2025년 들어 AGI 시대 대비를 위한 정책 및 기술 연구 결과를 논문, 블로그 등 다양한 형태로 발표 중
- 특히 Anthropic은 alignment 연구와 헌법형 AI 설계 등의 AI 안전 중심 연구를 지속 수행 중
- OpenAI, Google DeepMind, Anthropic 등은
- 영국 AI 보안연구소는 2025년 5월 향후 AI 안전 연구 아젠다 보고서 발간
- 싱가포르 AI 컨퍼런스에서 '국제 AI 안전 보고서'를 기준으로 연구 우선순위 및 종합 성과 정리 결과를 발표함
▸ 기업별 동향
| 기업 | 주요 활동 |
| OpenAI, DeepMind | AGI 대비 정책 및 기술 블로그/논문 발표 |
| Anthropic | AI 안전 관련 논문 지속 발표 (헌법형 AI, alignment 등) |
▸ 연구기관
| 기관 | 활동 |
| 영국 AI 보안연구소 | 2025년 5월 AI 안전 연구 아젠다 보고서 발간 |
| 싱가포르 AI 컨퍼런스 | '국제 AI 안전 보고서' 기반 우선순위 발표 |
728x90
'12. 메일진 > 7. AI Safety' 카테고리의 다른 글
| AI 안전성 - AI Alignment(인공지능 정렬) (0) | 2025.10.26 |
|---|---|
| AI 안전성 - 위험 관리 - 가디언 모델(Guardian Model) (0) | 2025.09.29 |
| AI 안전성 - 위험 관리 - 오픈AI, 세이프티 평가 허브(Safety Evaluations Hub) (0) | 2025.05.24 |
| AI 안전성 - 위험 관리 (0) | 2025.04.27 |
| AI 안전성 - 위험 관리 - TTA 범용 AI 안전성 강화를 위한 위험 관리 프레임워크 (0) | 2025.04.09 |




