07.AI
딥러닝 - 경사하강법 (Gradient Descent Method)
Mr. Slumber
2023. 11. 10. 07:04
728x90
반응형
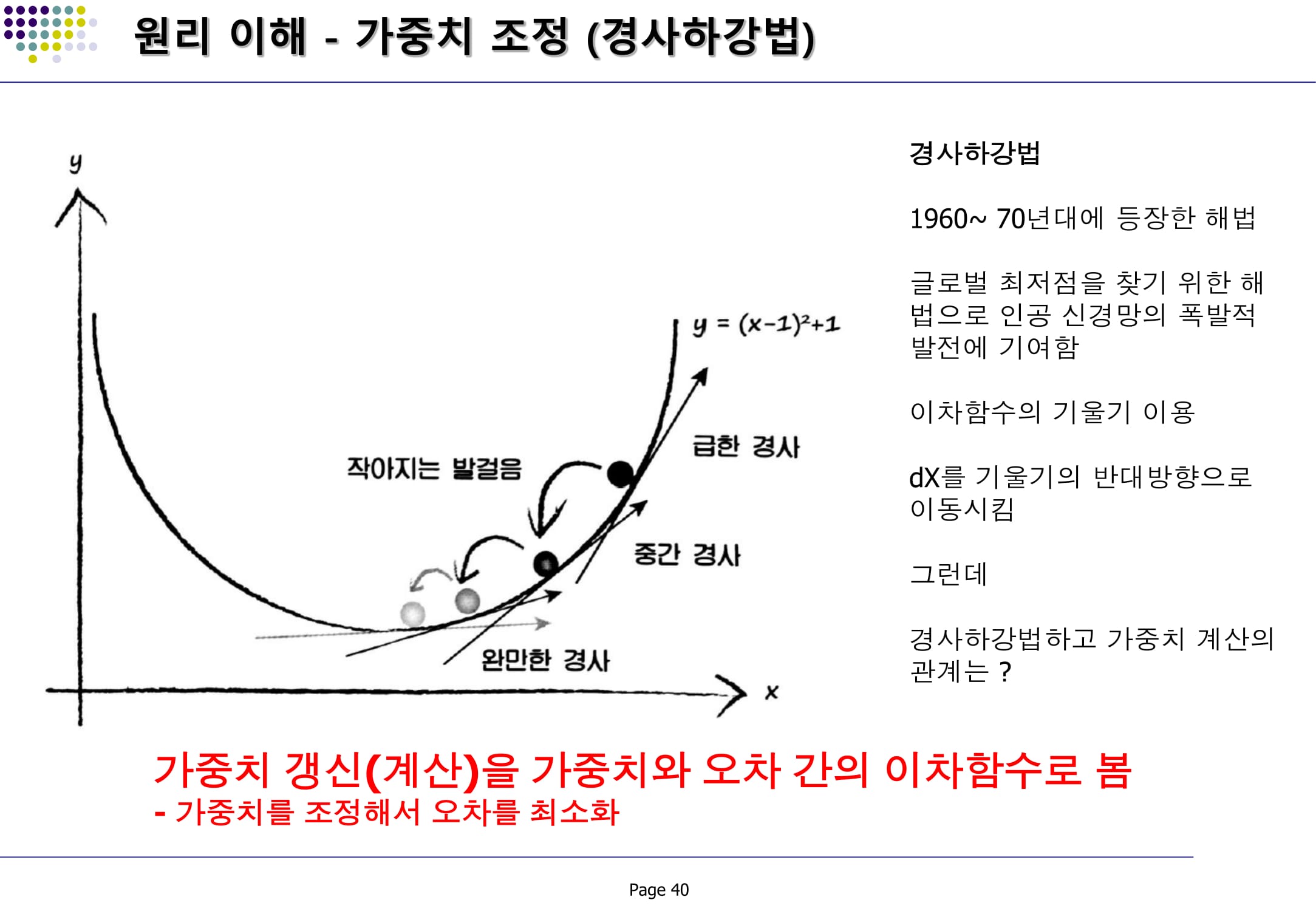
(정의)
- 주어진 함수의 최소값을 찾을 수있는 최적화 알고리즘
-신경망의 연결 가중치 최적화를 위해 에러함수의 경사(에러함수 미분)가 하강하는 방향을 관찰하고 그 쪽으로 조금씩 이동해가면서 검토를 반복하는 기법(신경망의 연결 가중치 최적화)
- 에러함수의 미분을 통해 에러가 감소하는 방향으로 조금씩 움직여가는 알고리즘
[key factor] 에러함수 미분, 초기값 선택, local minima(지역 최소값)/global minima, 경사하강법의 문제 해결 기법(확률적 경사하강법, 모멘텀 등)




Stochastic Gradient Descent 또는 간단히 SGD :하이퍼 매개변수를 통해 기계학습 알고리즘을 학습하는데 사용되는 최적화 알고리즘
샘플: 단일 데이터 행 (인스턴스, 관측, 입력 벡터 또는 피쳐 벡터)
배치 크기: 내부 모델 매개 변수를 업데이트하기 전에 수행 할 샘플 수를 정의하는 하이퍼 매개 변수
-
일괄 그라데이션 하강 . 배치 크기 = 훈련 세트의 크기
-
확률 적 경사도 . 일괄 처리 크기 = 1
-
미니 배치 그라디언트 하강 . 1 <배치 크기 <트레이닝 세트의 크기
배치 크기: 모델이 업데이트되기 전에 처리 된 샘플 수
에포크 수: 학습 데이터 세트를 통과 한 전체 패스 수






학습이잘안돼! 겨우되어도융통성이없다?! Underfitting
덜하거나 Overfitting 과하거나 (하여간적당히가없어요)
도대체학습은언제끝나는건가?Slow 느리거나













(https://dawn.cs.stanford.edu/2018/03/09/low-precision/?utm_campaign=Revue%20newsletter&utm_medium=Newsletter&utm_source=Deep%20Learning%20Weekly
HALP: High-Accuracy Low-Precision Training · Stanford DAWN
HALP: High-Accuracy Low-Precision Training by Chris De Sa, Megan Leszczynski, Jian Zhang, Alana Marzoev, Chris Aberger, Kunle Olukotun, and Chris Ré 09 Mar 2018 Using fewer bits of precision to train machine learning models limits training accuracy—or d
dawn.cs.stanford.edu
728x90