07.AI
워드 임베딩 (구글)
Mr. Slumber
2020. 5. 29. 11:48
728x90
반응형
1. 단어 수준 임베딩 모델 : 단어를 백터화, 단어 간의 유사도 측정
- 예측 기반 : NPLM, Word2Vec, FastText 등
- 행렬분해 기반 : LSA, GloVe, Swivel 등
2. 문장 수준 임베딩 모델 : 문서(문장)을 벡터화, 문서 간의 유사도 측정
- 확률 기반 : LDA
- 행렬분해 기반 : LSA
- 뉴럴네트워크 기반 : Doc2Vec, ELMo, GPT, BERT

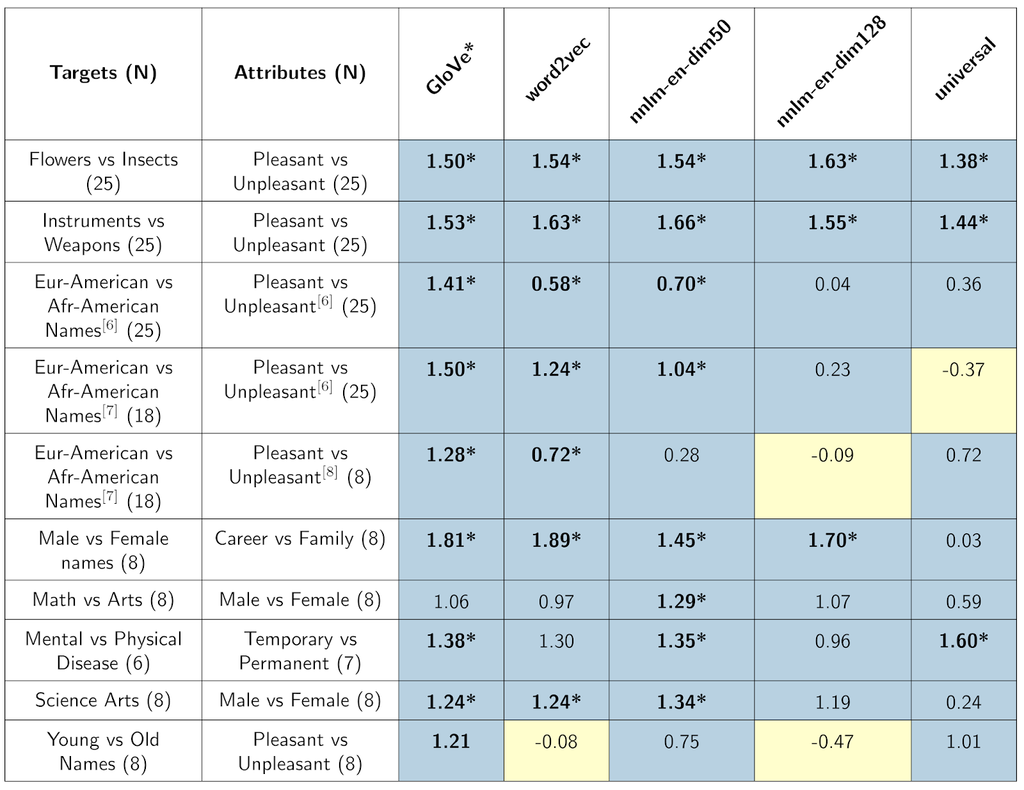
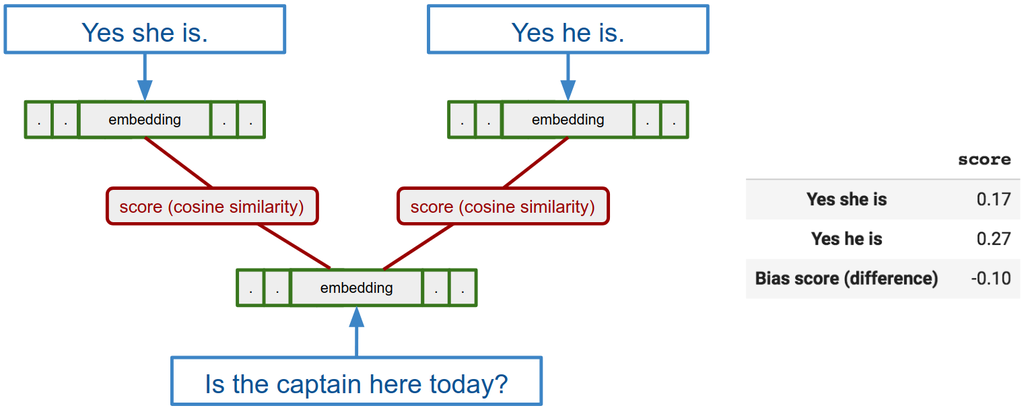
https://developers.googleblog.com/2018/04/text-embedding-models-contain-bias.html
Text Embedding Models Contain Bias. Here's Why That Matters.
Human data encodes human biases by default. Being aware of this is a good start, and the conversation around how to handle it is ongoing. At Google, we are actively researching unintended bias analysis and mitigation strategies because we are committed to
developers.googleblog.com
728x90