12. 메일진/5. AI 벤치마크
성과측정 - AI 검증 및 평가 - AI 에이전트 DeepSWE
Mr. Slumber
2026. 5. 31. 11:09
728x90
반응형
2026.5.30
[독창적이고 장기적인 엔지니어링 과제에서 최첨단 코딩 에이전트의 성능 측정]
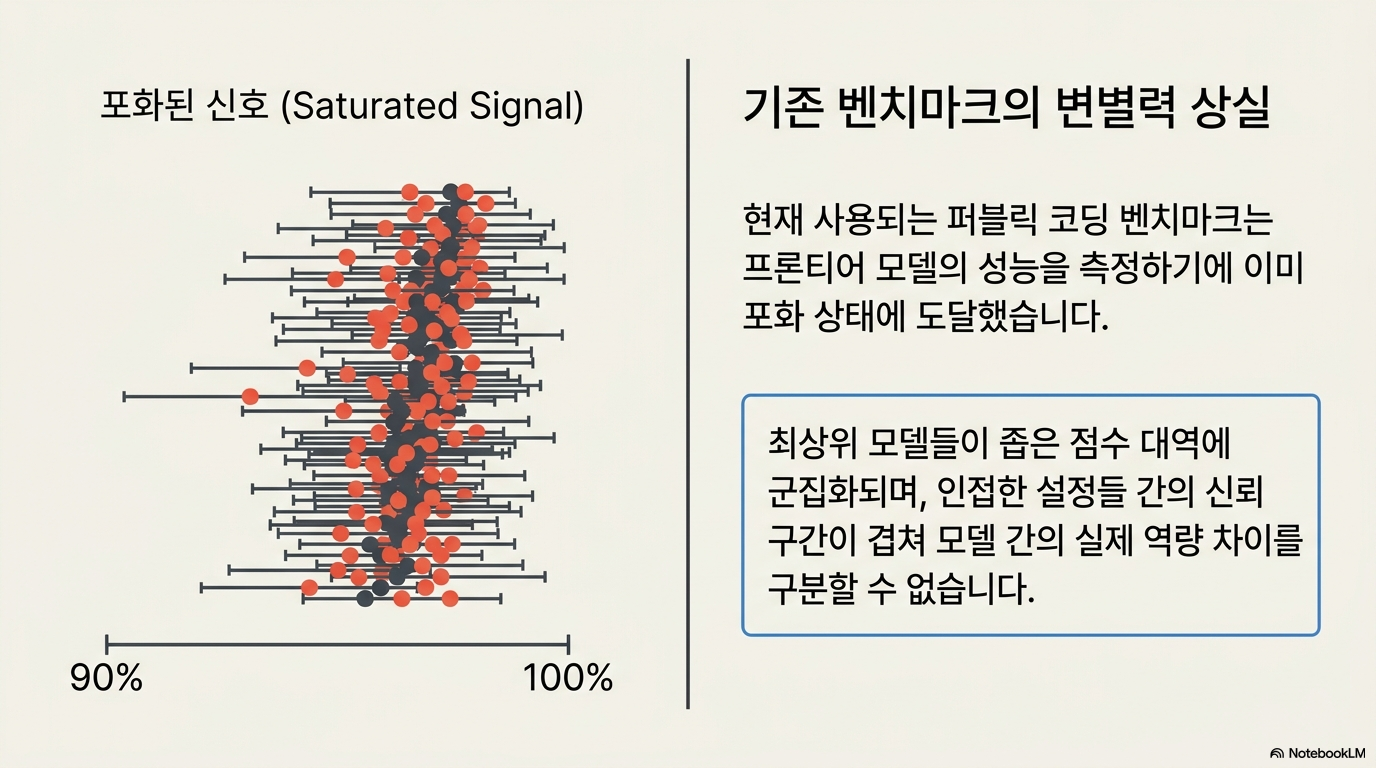
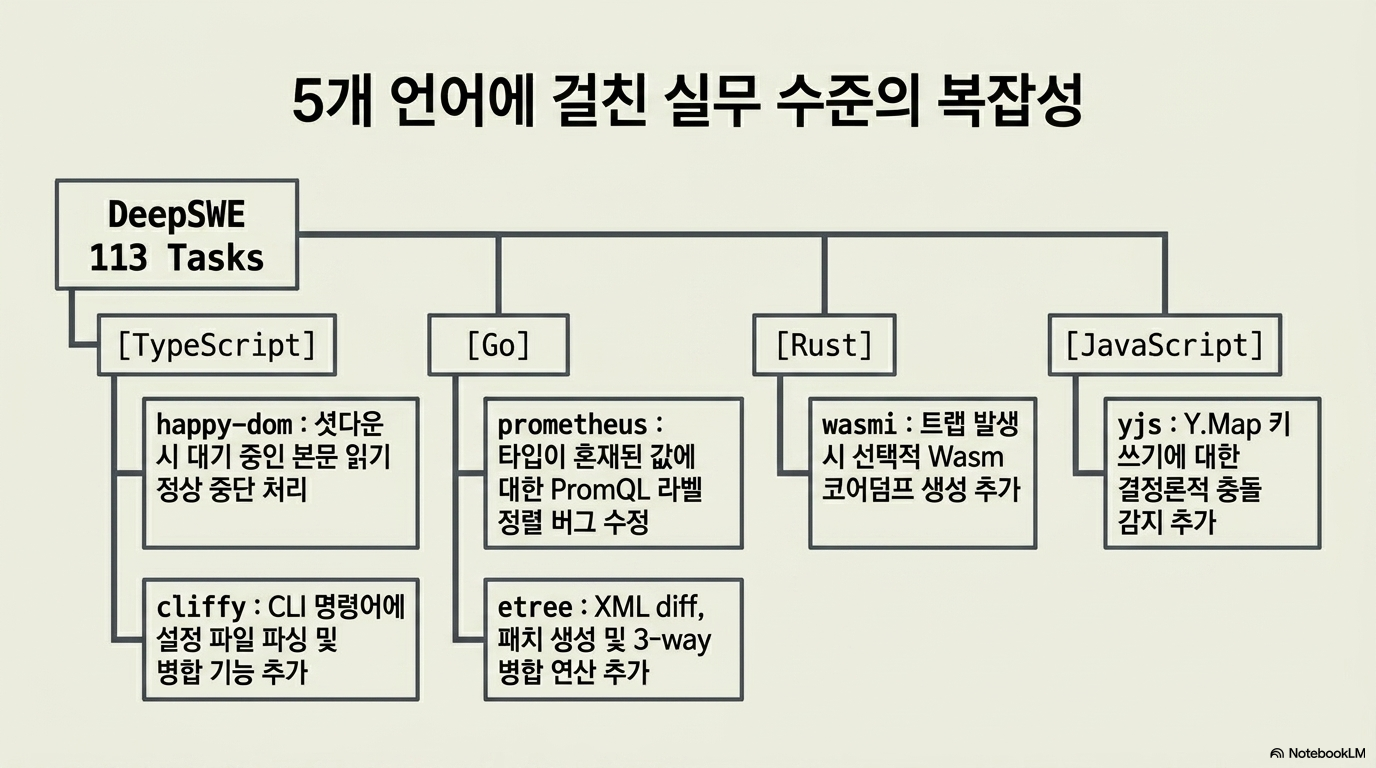
DeepSWE는 기존 코딩 벤치마크들의 변별력이 한계에 도달함에 따라, 최첨단 AI 모델들의 실질적인 개발 역량을 정교하게 측정하기 위해 설계된 차세대 소프트웨어 엔지니어링 평가 도구입니다. 이 시스템은 학습 데이터와의 중복이 없는 독창적인 과제와 수동으로 작성된 검증 도구를 활용하여, 모델이 단순히 정답을 암기했는지 아니면 실제 기술적 복잡성을 해결할 수 있는지를 엄격하게 시험합니다. 5개 언어에 걸친 다양한 저장소와 방대한 코드 출력량을 요구하는 과제들은 현재 상용화된 언어 모델들 간의 명확한 성능 격차를 드러내는 지표가 됩니다. 결과적으로 이 텍스트는 현실 세계의 공학적 난제들을 투영함으로써, 인공지능 에이전트가 도달한 기술적 성숙도를 객관적으로 증명하는 데 목적을 두고 있습니다.









728x90