인공지능 - 보안 - 적대적 머신러닝(ML): 공격 및 완화에 대한 분류와 용어 가이드라인
NIST AI 100-2e2023
1) 회피 공격(Evasion attack)
(개념) AI시스템이 배포된 후 발생한다. 입력을 변경해 시스템이 응답하는 방식을 변경하는 공격방식
학습이 완료된 정상적인 학습 모델에 사람이 알아채기 어려운 작은 차이를 입력 데이터에 추가하여 모델이 예상치 못한 결과를 도출하도록 유도하는 공격
- AI 시스템 배포 후 발생하는 회피 공격은 입력을 변경하여 시스템이 이에 응답하는 방식을 변경하려고 시도
자율주행자동차가 인식하는 정지 표시판을 속도제한 표지판으로 잘 못 해석하게 하는 식이다. 혼란스러운 차선 표시를 만들어 차량이 도로를 벗어나게 하는 형태의 공격
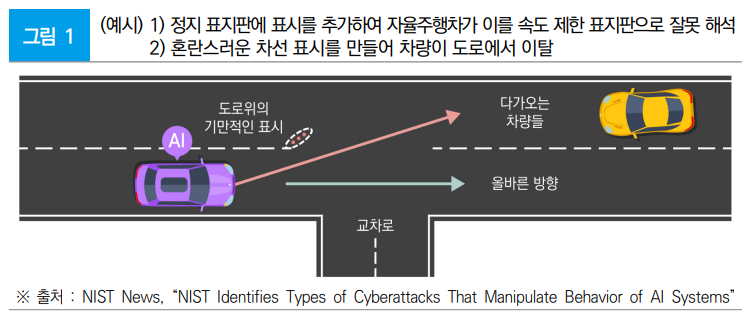
2) 중독 공격(Poisoning attack)
(개념)
기계학습 시스템의 동작을 의도적으로 왜곡하기 위해 학습 단계에서 학습 데이터를 조작하는 공격
손상된 데이터를 삽입해 AI시스템 훈련 단계에서 발생한다. 적이 훈련 데이터 세트를 조작하는 공격
- 회피공격과 달리 직접 학습과정에 개입하여 학습 모델을 공격하고 학습 데이터를 조작・손상시켜 부적절한 판단 결과를 유도
※ (예시) 챗봇에게 악의적 발언을 학습하여 인종차별과 욕설을 남발
공격자가 ML 모델에 부정확하거나 잘못 해석된 데이터를 공급해 잘못된 예측을 내놓게 만든다. 공격자가 훈련 데이터 중 일부에 부적절한 내용을 넣는다. AI 모델이 사용하는 데이터세트의 0.1%만 중독해도 성공적인 조작으로 이어질 수 있는 것으로 나타났다. 공격자는 위키피디아(Wikipedia)와 같은 크라우드 소스 정보 저장소 등을 악용해 LLM 모델을 간접적으로 조작할 수도 있다.
3) 남용 공격(Abuse attack)
(개념) AI 시스템의 학습에 관여되는 웹페이지나 온라인 문서 등 소스에 잘못된 정보 삽입 등을 통해 공격
- 중독 공격과 달리 AI 시스템의 의도된 용도를 변경하기 위해 합법적이지만 손상된 소스를 통해 AI에게 잘못된 정보 제공을 시도
피싱 이메일을 생성하거나 악성코드 작성과 같이 악성 콘텐츠를 생성하기 위해 AI 도구를 무기화하는 것이 포함된다. 실제로 다크웹에서 프러드(Fraud)GPT나 웜(Worm)GPT와 같이 사이버 범죄를 지원하는 LLM 서비스가 나왔다.
4) 프라이버시 공격(Privacy attack)
(개념) AI 시스템 배포 중에 발생하는 공격으로 AI 시스템 또는 학습 데이터에 대한 민감정보를 학습하여 이를 오용하려는 시도
- 공격자는 챗봇에게 합법적 질문을 한 다음 답변을 사용하여 모델을 리버스 엔지니어링 후 취약점을 찾거나 소스 추측 가능
※ 온라인상에서 데이터에 원하지 않는 예제를 추가하면 AI가 부적절하게 행동할 수 있으며, 결과가 발생한 후에는 AI가 원하지 않는 특정 예제를 학습하지 못하게 만드는 것이 어려울 수 있음
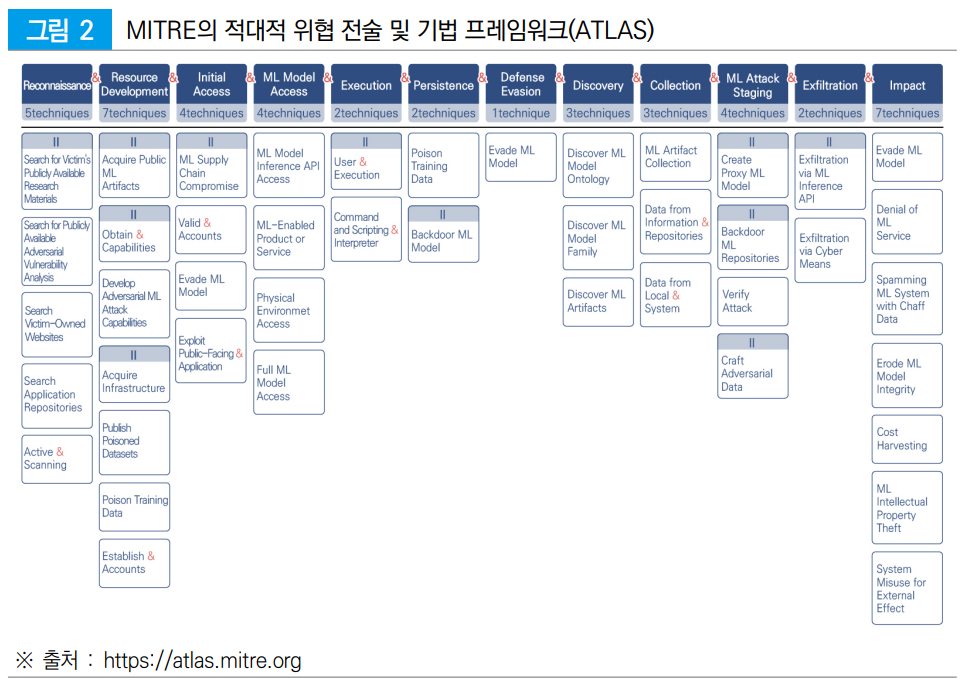
※ MITRE의 적대적 위협 전술 및 기법 프레임워크(ATLAS :Adversarial Threat Landscape for Artificial-Intelligence Systems)에서는 ATT&CK* 프레임워크를 모델로 하여 AI에 대한 적대적 위협 공격 전술과 기술・기법을 14개 공격 전술 및 82개 기계학습 기술・기법으로 정리한 매트릭스를 제시
* ATT&CK(Adversarial Tactics, Techniques, and Common Knowledge)는 사이버 공격방법과 기술의 관점으로 분석하여 체계적으로 분류하고 설명
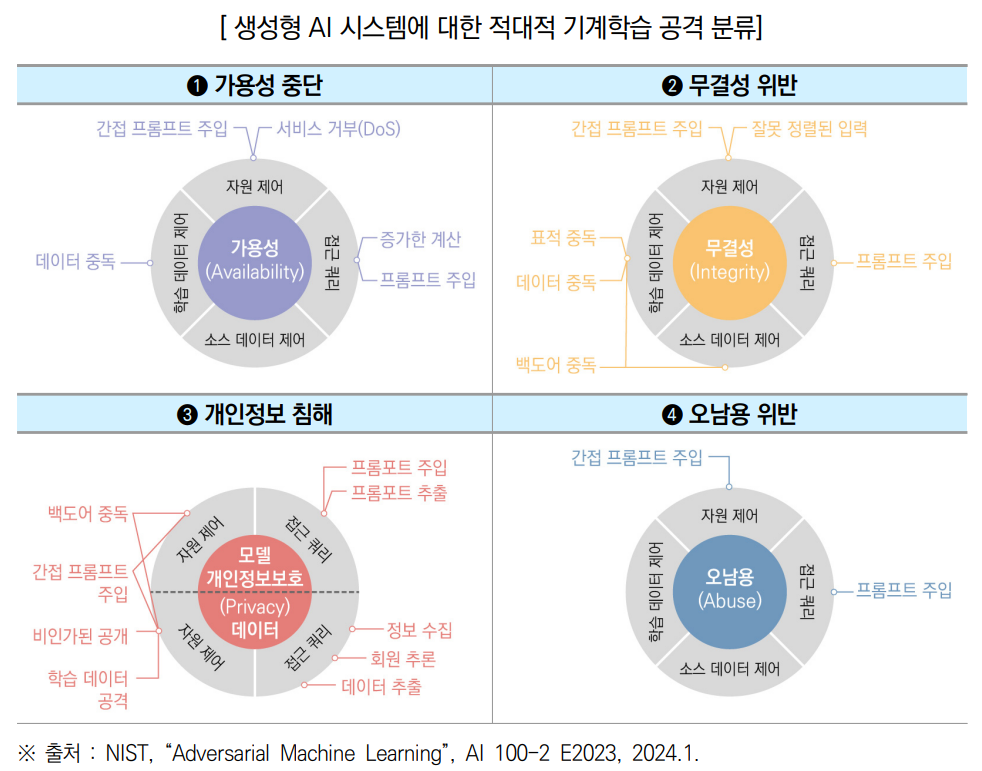
공격자의 목표에 따라 생성형 AI시스템에 대한 적대적 기계학습 공격을
❶가용성 중단, ❷무결성 위반, ❸개인정보 침해, ❹오남용 위반으로 분류
○ 오남용 위반은 생성형 AI 시스템에만 해당되는 공격자 목표로 공격자는 증오심 표현, 차별 조장, 특정집단 폭력 선동 등 이미지・텍스트 또는 악성 코드를 생성하여 공격에 활용
공격자의 능력에 따라 주요 기능( ❶학습데이터 제어, ❷접근 쿼리 ❸소스코드 제어, ❹자원 제어)을 활용
➊ (학습데이터 제어) 공격자는 학습 샘플을 삽입・수정하여 학습 데이터의 하위 집합 제어 가능 ➡ 데이터 중독 공격에 활용
➋ (접근 쿼리) 공격자는 모델에서 특정 동작을 유도하기 위해 모델에 쿼리를 통해 입력값을 제출하여 출력값을 수신 가능 ➡ 프롬프트 주입*(PROMPT INJECTION), 프롬프트 추출(PROMPT EXTRACTION) 및 모델 도용 공격에 활용
* 프롬프트 주입 공격 : 조작한 프롬프트를 주입하여 모델의 출력을 의도대로 실행하게 하는 것
※ 일반적으로 생성형 AI 모델과 애플리케이션(예: RAG)을 API 키를 통해 접근이 제어되는 클라우드 호스팅 서비스로 배포하는 경우에 활용
➌ (소스코드 제어) 공격자는 오픈소스 난수 생성기, 서드파티 라이브러리 등 기계학습 알고리즘의 소스 코드 수정이 가능 - 공격자는 오픈소스 모델 저장소에서 악성 모델을 만들거나 역직렬화 형식이 포함된 악성 코드로 모델을 포장(wrapping) 가능
※ 역직렬화(dedeserialization) : 직렬화*의 반대로 특정 포맷 상태를 다시 데이터로 변환하는 과정
* 직렬화(serialization) : 데이터 스토리지 문맥에서 데이터 구조나 오브젝트 상태를 동일하거나 다른 컴퓨터 환경에 저장하고 나중에 재구성할 수 있는 포맷으로 변환하는 과정
➍ (자원 제어) 공격자는 런타임 시 생성형 AI 모델에 의해 수집될 리소스(예: 문서, 웹 페이지)를 수정 가능 ➡ 간접 프롬프트 주입(Indirect Prompt Injection) 공격에 활용
생성형 AI 시스템의 학습 단계에 따른 공격
(파운데이션 모델의 사전 학습 단계, AI 모델의 미세 조정 단계)에 따라
❶ 학습시간(Training-time) 공격
❷ 추론시간(Inference-time) 공격으로 분류
❶ (학습 시간 공격) 파운데이션 모델은 일반적으로 공개된 소스에서 데이터를 스크래핑함으로 인해 공격자가 학습 데이터의 하위 집합을 제어하는 중독 공격에 취약
※ 공격자가 선별되지 않은 웹 규모 학습 데이터 세트의 0.001%만을 임의로 중독시켜 모델에서 표적 오류를 유도할 수 있음을 입증 (출처 : Nicholas Carlini. “Poisoning the unlabeled dataset of Semi- Supervised learning”, 30th USENIX Security Symposium)
- AI 모델 미세 조정 단계는 공격자의 지식과 능력에 따라 중독 공격에 취약할 수 있음
❷ (추론 시간 공격) 대형언어모델(이하, LLM) 및 검색 증강 생성(이하, RAG)* 애플리케이션은 데이터 및 작업지시(instruction)에 대한 별도 채널을 제공하지 않아 데이터 채널을 사용한 추론 시간 공격 가능
* RAG(Retrieval-Augmented Generation) : LLM의 출력을 최적화하기 위해 응답을 생성하기 전 학습 데이터 소스를 신뢰할 수 있는 지식 베이스를 참조하는 기법
- LLM・RAG 모델 공격은 Ⓐ 모델 작업지시(Model Instruction)를 통한 정렬, Ⓑ 컨텍스트별Contextual*) 퓨샷(few-shot**) 학습, Ⓒ 서드 파티 (3rd Party) 소스에서 런타임(rumtime) 데이터 수집, Ⓓ 출력 처리, Ⓔ 에이전트를 통해 발생
* 컨텍스트(context) : AI가 특정 환경을 이해하고 그에 따라 적절한 방식으로 행동하기 위해 주어지는 맥락
** Few-shot learning : 모델이 매우 제한된 양의 학습 데이터만을 사용하여 새로운 작업을 수행할 수 있게 하는 학습 방식
zero-shot learning : 모델이 학습 데이터 셋에서 본 적 없는 새로운 카테고리나 작업에 대해 인식할 수 있도록 하는 학습 방식

https://charstring.tistory.com/947
인공지능 - 보안 - 적대적 예제 (Adversarial Examples)
charstring.tistory.com
https://zdnet.co.kr/view/?no=20240110111503
AI 해킹을 막을 완벽한 방법은 없다
공격자는 인공지능(AI) 시스템에 의도적으로 접근해 오작동을 일으킬 수 있는데 이에 대한 완벽한 방어책은 없다. 미국 국가표준기술연구소(NIST)는 '적대...
zdnet.co.kr
https://csrc.nist.gov/pubs/ai/100/2/e2023/final
AI 100-2 E2023, Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations | CSRC
Publications Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations Documentation Topics Date Published: January 2024 Author(s) Apostol Vassilev (NIST), Alina Oprea (Northeastern University), Alie Fordyce (Robust
csrc.nist.gov
NIST, 악마적(?) 기계 학습에 대한 새로운 가이드라인 발표
두번째 책에는 AI보안을 추가! 인생첫책 전략적 해커에 이어서 현재 집필중인 두번째 책에는 3~4개 Chapter를 추가하려고 준비중에 있다고 했었는데 그중의 한 아이템이 바로 AI보안이었다. ChatGPT로
tedlee.be
https://www.fsec.or.kr/bbs/detail?menuNo=242&bbsNo=11551
금융보안원
[금보원2024-3Q] 전자금융과 금융보안 제37호 보안연구부 2024-09-09
www.fsec.or.kr